- A+
所属分类:elasticsearch
ELK?
You Know, For Search!
1.全文搜索
2.结构化数据实时统计
3.数据分析
4.复杂语言处理
5.地理位置
6.对象间关联关系等
7.甚至还可以数据建模
等功能….
基于对日志的实时分析,可以随时掌握服务的运行状况、统计 PV/UV、发现异常流量、分析用户行为、查看热门站内搜索关键词等
1.How To ELK?
本文基于ELK stack 5.4版本
2.从官方架构图开始
官方ELK架构图
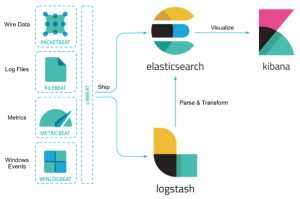
Beats: 日志收集器的统称, 其中FileBeat用于收集文件日志; Logstash: 日志收集、过滤、转发的中间件,各类日志统一收集/过滤/转发Elasticsearch Elasticsearch: 分布式、可扩展、实时的搜索与数据分析引擎; Kibana: 是一个可视化工具,主要负责查询 Elasticsearch 的数据并以可视化的方式展现给业务方,比如各类饼图、直方图、区域图等;
2.1 简单了解各个业务组件
2.1.1 FileBeat
# 使用方法 1. 下载-解压-进入解压缩目录. 2. 编辑 `filebeat.yml`, filebeat.full.yml为完整版的配置文件. 3. 启动方式 `sudo ./filebeat -e -c filebeat.yml`.
# 解析Nginx访问日志: 获取日志-存储到redis filebeat.prospectors: - input_type: log paths: - /track/nginx/logs/sx3/access.log # `日志文件地址` encoding: utf-8 document_type: sx3_nginx_access # `打标签` scan_frequency: 10s harvester_buffer_size: 16384 #multiline: # pattern: '^\d' # match: after tags: ["sx3"] ignore_older: 24 output.redis: enabled: true hosts: ["xxxxxx:6379"] # `redis地址` port: 6379 key: sx3_nginx_access #password: db: 0 datatype: list worker: 1 loadbalance: true # `负载均衡` timeout: 5s max_retries: 3 bulk_max_size: 2048 #ssl.enabled: true #ssl.verification_mode: full #ssl.supported_protocols: [TLSv1.0, TLSv1.1, TLSv1.2] #ssl.certificate_authorities: ["/etc/pki/root/ca.pem"] #ssl.certificate: "/etc/pki/client/cert.pem" #ssl.key: "/etc/pki/client/cert.key" #ssl.key_passphrase: '' #ssl.cipher_suites: [] #ssl.curve_types: [] logging.to_files: true logging.files: path: /docker_data/elk_data/filebeat name: filebeat rotateeverybytes: 80485760 keepfiles: 7
2.1.2 LogStash
# 使用方法
1. 下载-解压-进入解压缩目录
2. `mkdir conf&& cd conf&& touch logstash-simple.conf`
3. vim logstash-simple.conf
添加: 标准输入-标准输出测试
input { stdin { } }
output {
#elasticsearch { hosts => ["localhost:9200"] }
stdout { codec => rubydebug }
}
4. 启动方式 `bin/logstash -f logstash-simple.conf`
# LogStash常用函数
filter{} 常用函数解析
grok{} 是一个解析日志数据的好插件
mutate{} 可以用于处理数据类型相关的转换
geoip{} 可以根据日志中的 IP 数据直接解析出更加详细直观的位置数据
date{} 用于将日期解析为 @timestamp
useragent{} 可以更佳的获得用户浏览器的属性
Logstash语法会有一些坑, 特别是如果你线上的Nginx日志还不是默认格式的时候
推荐使用grokdebug在线测试
默认logstash Grok全局变量
如何自定义logstash模式
# 自己写的几个例子, 可能有错, 欢迎指正, 后续更新
# 1.To redis
# 推荐使用`FileBeat`, 它更轻量级并且速度更快
# 但是,平常开发类的需求可以直接使用`logstash`搞定, 感觉会更方便
input {
stdin { }
file {
type => "sx3_nginx_access"
path => "/home/will/elk/logstash/access.log"
start_position => beginning
codec => multiline {
'negate' => true
'pattern' => '^\d'
'what' => 'previous'
}
}
}
output {
stdout { codec => rubydebug }
if [type] == "sx3_nginx_access" {
redis {
host => "localhost"
data_type => "list"
key => "sx3_nginx_access"
}
}
}
# 2.Nginx access log to elastic (PS: 获取`redis`的数据, 格式化后导入`ElasticSearch`)
input {
redis {
host => "10.117.44.44"
type => "sx3_nginx_access"
data_type => "list"
key => "sx3_nginx_access"
}
}
filter {
if [type] == "sx3_nginx_access" {
grok {
match => {
"message" => [
"%{BASE16FLOAT:upstream_response_time} \| %{COMBINEDAPACHELOG} %{GREEDYDATA:request_time}",
"%{NGINXCOMBINEDAPACHELOG}"
]
}
patterns_dir => ["/home/will/elk_stack/logstash/patterns"] # 自定义的模式匹配变量Dir
remove_field => [ "message" ]
}
mutate {
convert => ["response", "integer"]
convert => ["bytes", "integer"]
convert => ["responsetime", "float"]
convert => ["upstream_response_time", "float"]
convert => ["request_time", "float"]
gsub => ["referrer", "[\"]", ""]
gsub => ["agent", "[\"]", ""]
}
geoip {
source => "clientip"
target => "geoip"
add_tag => [ "sx3-geoip" ]
}
useragent {
source => "agent"
}
#date {
# match => [ "timestamp" , "yyyy/MM/dd HH:mm:ss" ]
# timezone => 'UTC'
#}
}
}
# 3. nginx_error_log模式匹配
cat nginx_error_log_format.conf
input {
redis {
host => "10.117.44.44"
type => "sx3_nginx_error"
data_type => "list"
key => "sx3_nginx_error"
}
}
filter{
if [type] == "sx3_nginx_error" {
grok {
match => {
"message" => [
"(?<timestamp>\d{4}/\d{2}/\d{2} \d{2}:\d{2}:\d{2}) \[%{DATA:err_severity}\] (%{NUMBER:pid:int}#%{NUMBER}: \*%{NUMBER}|\*%{NUMBER}) %{DATA:err_message}(?:, client: (?<client_ip>%{IP}|%{HOSTNAME}))(?:, server: %{IPORHOST:server})(?:, request: \"%{WORD:verb} (%{URIPATH:urlpath}%{URIPARAM:urlparam} HTTP/%{NUMBER:httpversion})\")(?:, host: %{QS:hostname})(?:, referrer: \"%{URI:referrer}\")",
"(?<timestamp>\d{4}/\d{2}/\d{2} \d{2}:\d{2}:\d{2}) \[%{DATA:err_severity}\] (%{NUMBER:pid:int}#%{NUMBER}: \*%{NUMBER}|\*%{NUMBER}) %{DATA:err_message}(?:, client: (?<client_ip>%{IP}|%{HOSTNAME}))(?:, server: %{IPORHOST:server})(?:, request: \"%{WORD:verb} (%{URIPATH:urlpath}%{URIPARAM:urlparam} HTTP/%{NUMBER:httpversion})\")(?:, upstream: \"%{URI:upstream}\")",
"(?<timestamp>\d{4}/\d{2}/\d{2} \d{2}:\d{2}:\d{2}) \[%{DATA:err_severity}\] (%{NUMBER:pid:int}#%{NUMBER}: \*%{NUMBER}|\*%{NUMBER}) %{DATA:err_message}(?:, client: (?<client_ip>%{IP}|%{HOSTNAME}))(?:, server: %{IPORHOST:server})(?:, request: \"%{WORD:verb} (%{URIPATH:urlpath}%{URIPARAM:urlparam} HTTP/%{NUMBER:httpversion})\")",
"(?<timestamp>\d{4}/\d{2}/\d{2} \d{2}:\d{2}:\d{2}) \[%{DATA:err_severity}\] (%{NUMBER:pid:int}#%{NUMBER}: \*%{NUMBER}|\*%{NUMBER}) %{DATA:err_message}(?:, client: (?<client_ip>%{IP}|%{HOSTNAME}))(?:, server: %{IPORHOST:server})(?:, request: \"%{WORD:verb} (%{URIPATH:urlpath} HTTP/%{NUMBER:httpversion})\")(?:, referrer: \"%{URI:referrer}\")",
"(?<timestamp>\d{4}/\d{2}/\d{2} \d{2}:\d{2}:\d{2}) \[%{DATA:err_severity}\] (%{NUMBER:pid:int}#%{NUMBER}: \*%{NUMBER}|\*%{NUMBER}) %{DATA:err_message}(?:, client: (?<client_ip>%{IP}|%{HOSTNAME}))(?:, server: %{IPORHOST:server})(?:, request: \"%{WORD:verb} (%{URIPATH:urlpath} HTTP/%{NUMBER:httpversion})\")(?:, upstream: \"%{URI:upstream}\")",
"(?<timestamp>\d{4}/\d{2}/\d{2} \d{2}:\d{2}:\d{2}) \[%{DATA:err_severity}\] (%{NUMBER:pid:int}#%{NUMBER}: \*%{NUMBER}|\*%{NUMBER}) %{DATA:err_message}(?:, client: (?<client_ip>%{IP}|%{HOSTNAME}))(?:, server: %{IPORHOST:server})(?:, request: \"%{WORD:verb} (%{URIPATH:urlpath} HTTP/%{NUMBER:httpversion})\")"
]
}
remove_field => [ "message" ]
}
date {
match => [ "timestamp" , "yyyy/MM/dd HH:mm:ss" ]
timezone => 'UTC'
}
}
}
output {
elasticsearch { hosts => ["xxx:9200"] index => "logstash-nginx-error-%{+YYYY.MM.dd}"}
stdout { codec => rubydebug }
}logstash 提供的默认的正则表达式, 但是不一定满足我们的需求
当遇到其他需要自定义的时候:
grok {
match => { "request" => '"%{WORD:verb} %{URIPATH:urlpath}(?:\?%{NGX_URIPARAM:urlparam})?(?: HTTP/%{NUMBER:httpversion})"' }
patterns_dir => ["/etc/logstash/patterns"] # 定义模式匹配的位置
remove_field => [ "message", "errinfo", "request" ]
}
}
模式匹配使用规则
%{PATTERN_NAME:capture_name:data_type}
patterns内容
cat /home/will/elk_stack/logstash/patterns/grok_patterns_extend
EMAIL [a-z_0-9.-]{1,64}@([a-z0-9-]{1,200}.){1,5}[a-z]{1,6}
NGINXCOMBINEDAPACHELOG %{BASE16FLOAT:upstream_response_time} \| %{IPORHOST:clientip} %{USER:ident} %{EMAIL:auth} \[%{HTTPDATE:timestamp}\] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{NUMBER:response} (?:%{NUMBER:bytes}|-) %
2.1.3 ElasticSearch
# 使用方法 1. 下载-解压-进入目录 2. vim config/elasticsearch.yml 更改配置文件 配置例子: grep -n '^[a-Z]' config/elasticsearch.yml custer.name: xzelk node.name: master node.master: true node.data: true node.attr.rack: r1 path.data: /docker_data/elk_data/elastic/data path.logs: /docker_data/elk_data/elastic/logs network.host: 0.0.0.0 http.port: 9200 discovery.zen.ping.unicast.hosts: ["10.117.44.44:9300"] 3.启动 ./bin/elasticsearch 4.检查 curl http://localhost:9200/
2.1.4 Kibana
# 使用方法 1. 下载-解压-进入目录-打开配置编辑器中的kibana.yml 2. 配置elasticsearch.url指向你的ElasticSearch实例 3. 启动: bin/kibana 4. 检查: http://localhost:5601

2.1.4 x-pack
x-park提供以下功能-除了Monitor组件(需要到官方注册s申请), 其它的都需要收费
更新license
由于认证收费, 所以曲线救国, Nginx上配置简单密码认证
配置地址
upstream kibana5 {
server 127.0.0.1:5601 fail_timeout=0;
}
server {
listen *:80;
server_name kibana_server;
access_log /var/log/nginx/kibana.srv-log-dev.log;
error_log /var/log/nginx/kibana.srv-log-dev.error.log;
ssl on;
ssl_certificate /etc/nginx/ssl/all.crt;
ssl_certificate_key /etc/nginx/ssl/server.key;
location / {
root /var/www/kibana;
index index.html index.htm;
}
location ~ ^/kibana5/.* {
proxy_pass http://kibana5;
rewrite ^/kibana5/(.*) /$1 break;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $host;
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/conf.d/kibana.myhost.org.htpasswd;
}
}
如果用户够多,当然你可以单独跑一个 kibana5 集群,然后在 upstream 配置段中添加多个代理地址做负载均衡。
htpasswd -c /$path/.htpasswd $username
3. 实践架构
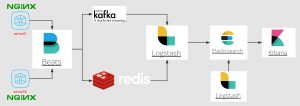
# 为了尽量保证数据完整性, 中间加了缓存 1. Filebeat 获取Nginx日志, 导入kafka 或者 redis 2. Logstash 获取对应redis队列中的数据format, 导入Elasticsearch 3. Kibana 设定到Elasticsearch的连接, 实时查询和可视化分析 整个架构可以横向扩展, redis/logstash/elasticsearch/kibana 都可以做集群
3.1 Elasticsearch集群配置
3.2 ELK 集群管理
3.2.1 集群管理API
# 集群健康状态
curl 'http://10.117.44.44:9200/_cat/health?v'
# 获取集群的一系列节点
curl 'http://10.117.44.44:9200/_cat/nodes?v'
# 列出所有的索引
curl 'http://10.117.44.44:9200/_cat/indices?v'
# 创建一个索引
curl -XPUT 'http://10.117.44.44:9200/customer?pretty'
# 往索引的某个类型中添加内容
# customer索引的external类型添加一个字典
curl -XPUT 'http://10.117.44.44:9200/customer/external/1?pretty' -d '
{
"name": "John Doe"
}'
{
"_index" : "customer",
"_type" : "external",
"_id" : "1",
"_version" : 1,
"created" : true
}
# 查找刚刚创建的数据
curl -XGET 'http://10.117.44.44:9200/customer/external/1?pretty'
{
"_index" : "customer",
"_type" : "external",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : { "name": "John Doe" }
}
# 更新文档
curl -XPUT 'localhost:9200/customer/external/1?pretty' -d '
{
"name": "Jane Doe"
}'
# 删除文档
curl -XDELETE 'localhost:9200/customer/external/2?pretty'
# 批处理
# 删除只要求要删除的文件的ID,然后,相应的源文件也就没有了
curl -XPOST 'localhost:9200/customer/external/_bulk?pretty' -d '
{"update":{"_id":"1"}}
{"doc": { "name": "John Doe becomes Jane Doe" } }
{"delete":{"_id":"2"}}
'
总结: ElasticSearch的restful语法大致如下 curl -X<REST Verb> <Node>:<Port>/<Index>/<Type>/<ID>
3.2.1 集群管理第三发库-cerebro
Github地址
Cerebro 是一个第三方的 Elasticsearch 集群管理软件,可以方便地查看集群状态, 以及一些集群管理工作
# 使用方法 1. 下载-解压-进入目录 2. 运行 bin/cerebro -Dhttp.port=1234 -Dhttp.address=127.0.0.1
安装后报错: max file limit
vim /etc/security/limits.conf * hard nofile 655360 * soft nofile 655360
安装后报错: vm bala bala bala….
vim /etc/sysctl.conf vm.max_map_count=2621440 #添加这一行
科普小知识-网站流量统计
UV(Unique visitor): 用户唯一性, 一天内同个访客多次访问仅计算一个UV; IP(Internet Protocol): IP唯一性, 一天内相同的IP地址多次仅被计算一次IP; PV(Page View):页面的浏览次数累计; VV(Visit View): 访问网站的次数累计;
- 安卓客户端下载
- 微信扫一扫
-

- 微信公众号
- 微信公众号扫一扫
-