- A+
设计思想
所有分布式系统都需要以某种方式处理一致性.一般的,可以将策略分为两组:试图避免不一致,和定义发生之后如何协调他们.后者对于适用这种方案问题来说非常强大,但对数据模型有比较严格的限制。因此这里研究第一类,以及如何应对网络故障。
为什么使用 Master
另一种选择是分布式哈希表(DHT),可以支持每小时数千个节点的离开和加入,他可以在不了解底层网络拓扑的异构网络中工作,查询响应时间大约为4到10跳(中转次数),但是在相对稳定的对等网络中,Master模式会更好
Elasticsearch的典型场景中的另一个简化是集群中没有那么多节点。 通常,节点的数量远远小于单个节点能够维护的连接数,并且网格环境不必经常处理节点加入和离开。 这就是为什么领导者的做法更适合Elasticsearch。
选举算法
不重复造轮子,最好实现一个众所周知的算法,其中的优点和缺陷是已知的
Bully算法
Leader选举的基本算法之一。 它假定所有节点都有一个惟一的ID,该ID对节点进行排序。 任何时候的当前Leader都是参与集群的最高id节点。 该算法的优点是易于实现,但是,当拥有最大 id 的节点处于不稳定状态的场景下会有问题,例如 Master 负载过重而假死,集群拥有第二大id 的节点被选为 新主,这时原来的 Master 恢复,再次被选为新主,然后又假死…
elasticsearch 通过推迟选举直到当前的 Master 失效来解决上述问题,但是容易产生脑裂,再通过 法定得票人数过半 解决脑裂
Paxos算法
Paxos实现起来非常复杂,但非常强大,尤其在什么时机,以及如何进行选举方面的灵活性比简单的Bully算法有很大的优势,因为在现实生活中,存在比网络链接异常更多的故障模式。
选主流程
只有一个 Leader将当前版本的全局集群状态推送到每个节点。 ZenDiscovery(默认)过程就是这样的:
- 每个节点计算最低的已知节点ID,并向该节点发送领导投票
- 如果一个节点收到足够多的票数,并且该节点也为自己投票,那么它将扮演领导者的角色,开始发布集群状态。
- 所有节点都会参数选举,并参与投票,但是,只有有资格成为 master 的节点的投票才有效.
有多少选票赢得选举的定义就是所谓的法定人数。 在弹性搜索中,法定大小是一个可配置的参数。 (一般配置成:可以成为master节点数n/2+1)
详细流程
路径:discovery.zen.ZenDiscovery#innerJoinCluster
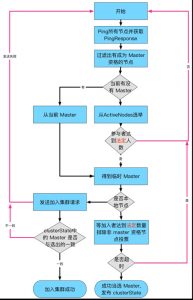
在 es 中,发送投票就是发送加入集群请求.在 handleJoinRequest 过程统计投票,收到的连接被存储到 pendingJoinRequests.
在 checkPendingJoinsAndElectIfNeeded 中检查投票是否足够,其中会过滤掉没有 Master 资格节点的投票
int pendingMasterJoins = 0;
synchronized (pendingJoinRequests) {
for (DiscoveryNode node : pendingJoinRequests.keySet()) {
if (node.isMasterNode()) {
pendingMasterJoins++;
}
}
}
- Ping所有节点并获取PingResponse
pingService.pingAndWait(pingTimeout); - 过滤有成为 Master 资格的节点
- 创建了三个列表
- ActiveNodes: ping 结果 + localnode
- NodesJoinedAtleastOnceBefore: 如果以前已加入群集,则将其添加到此列表中(内存已有 clusterState, 非磁盘中的),可能包含 localnode
- pingMasters: 主节点列表, ping 返回的节点中指示的 master 节点,正常是重复的同一个节点,不包含 localnode,因为可能会在没有任何其他节点的检查/验证的情况下,在ZenDiscover # innerJoinCluster()中进行选举
其中,joinedOnceActiveNodes.size <= activeNodes.size,差别在于是否含有 localnode, 其他的内容都一样,都是来自ping 的结果.
- 如果pingMasters不为空,当前集群认为存在 Master
- 在这些pingMasters中选择主。
- 此列表不包含本地节点
如果 pingMasters 为空, 当前集群认为不存在 Master - 首先在 NodesJoinedAtleastOnceBefore 中选举
- 如果没有选中,则在 ActiveNodes 上进行选举。
- 选举算法就是把 node 列表根据 nodeid排序,取第一个
- 现在已经选出了一个 master, 但只是临时的,准备向其投票
- 如果localnode被选为Master
- 等待非主节点的连接到足够数量(投票达到法定人数),以完成选举
nodeJoinController.waitToBeElectedAsMaster - 超时后还没有满足数量的join请求,则选举失败,需要新一轮选举
- 成功后发布新的 clusterState
- 等待非主节点的连接到足够数量(投票达到法定人数),以完成选举
- 如果其他节点被选为Master
- 停止累加连接
- 向 Master 发送加入请求,请求发送完毕就认为成功,无论 Master 如何处理.通过集群状态更新线程完成连接
如果收到的clusterState 中, Master 不是之前选出的,则重新选举.
membership.sendJoinRequestBlocking(masterNode, clusterService.localNode(), joinTimeout); - clusterService.submitStateUpdateTask("finalize_join (" + masterNode + ")", new ClusterStateNonMasterUpdateTask()
什么时候触发选主?
- 集群启动
- Master 失效非 Master 节点运行的 MasterFaultDetection 检测到 Master 失效,在其注册的 listener 中执行 handleMasterGone,执行 rejoin 操作,重新选主.注意,即使一个节点认为 Master 失效也会进入选主流程
为什么不用 zk?
elasticsearch 第一版发与2010,zk2008,也许因为当时 zk 不流行?
如何获取最新数据
现在 Master 已成功当选,但是他未必有最新的 clusterState 信息,这些信息如何得到?
gateway 模块负责 clusterState 持久化和恢复,Master 节点在当选后,会通过下面的流程获取到集群最新 clusterState:
1. 枚举集群中有资格成为 Master 的节点列表
2. 通过listGatewayMetaState获取这些节点上存储的 clusterState
3. 对比这些节点的 clusterState 版本号,选择最新的作为 clusterState 并应用.
一个小问题
技术分析会议中有同学提出一个有趣的问题:
假设10台机器组成的集群产生网络分区,3台一组,7台一组,产生分区前, Master位于3台中的一个,此时7台1组的节点会重新并成功选取 Master, 这种情况如何处理?
ES 对应的处理机制是这样的:
当有节点从集群离开时, Master 节点会检查一下当前集群总节点数是否具备法定节点数(过半),如果不具备,他会重新加入集群,放弃 Master 资格,因此不会产生双主.
参考链接:
- https://www.elastic.co/blog/found-leader-election-in-general
- http://www.cnblogs.com/zziawanblog/p/6577383.html
- https://www.linkedin.com/pulse/elasticsearch-zen-discovery-explained-gaurav-kukal
- 安卓客户端下载
- 微信扫一扫
-

- 微信公众号
- 微信公众号扫一扫
-