- A+
自从接触 Docker 之后,对 Docker 简直是爱不释手,做什么都是行云流水。遇到部署开源软件需求,第一时间想到的都是有没有现成的 Docker 镜像?能不能直接拉起来使用?
所以,这次网平的 ES 集群的重建,全部使用 DockerHub 已有镜像完成部署,整个过程变得非常简单!本文将分享详细的部署过程,希望对 ES 感兴趣或即将入坑 ES 的同学带来一些帮助。
一、整体架构
这里,我先给出本文最终的整体架构,让大家有一个清晰的部署思路:

角色分离:本文分享的 ES 架构中,特意将 Master 和 Client 独立出来,后续节点的重启维护都能快速完成,对用户几乎没有影响。另外将这些角色独立出来的以后,对应的计算资源消耗也就从 Data 节点剥离了出来,更容易掌握 Data 节点资源消耗与写入量和查询量之间的联系,非常有利于集群后续的容量管理和规划,算是一个比较成熟的中小型方案,准备正儿八经开搞的同学可以参考部署。
Ps:详细的 ES 角色职责说明可以查看官方文档。
数据流向:Beats 或自研系统上报日志到 Kafka,然后 Logstash 从 Kafka 读取数据写入 ES.Client,最终数据存放到 ES.Data 节点。用户可以通过 Kibana 或 ES.Client 的 Restful 接口查询数据。
本文涉及的 IP 的角色属性清单:
| 名称 | 服务器 IP | 角色 | 备注 |
| Docker 仓库 | 192.168.1.111 | Docker/registry | 内网私有仓库,需要外网 |
| Kafka Cluster | 192.168.1.100 | Kafka/Zookeeper | |
| 192.168.1.101 | Kafka/Zookeeper | ||
| 192.168.1.102 | Kafka/Zookeeper | ||
| ES Cluster | 192.168.2.100 | ES: Master/Client/Kibana | 128Gx35 核 |
| 192.168.2.101 | ES: Master/Client/Kibana | ||
| 192.168.2.102 | ES: Master/Client/Kibana | ||
| 192.168.3.100 | ES: DATA |
64Gx32 核 2TBx12
Ps:预算充足的强烈推荐上 SSD 硬盘,可以极大的提高集群性能!
|
|
| 192.168.3.101 | ES: DATA | ||
| 192.168.3.102 | ES: DATA | ||
| 192.168.3.103 | ES: DATA |
本文涉及的部分参数简单解释(更多详细解释请咨询搜索引擎):
# docker参数 ================================================== --name 指定docker容器的名称 --net=host 使用host网络模式(和宿主机一个网络) --restart always docker 异常退出后自动重启 --volume / -v 挂载本地目录,格式 /src:/dst -e 指定docker启动后环境变量(env) --privileged 让docker可以拥有root权限 --ulimit nofile 系统文件句柄打开数量限制 --ulimit memlock 最大锁定内存地址空间,-1表示不限制 --memory 限制docker内存 --memory-swap 限制docker虚拟内存,-1 为不限制,共用宿主机swap --cpuset-cpus 指定docker绑定的CPU TERM=dumb 让docker里面可以执行top命令 # Zookeeper docker参数 ================================================== ZOO_PORT 配置zookeeper的服务端口 ZOO_DATA_DIR 配置zookeeper的文件存放目录 ZOO_DATA_LOG_DIR 配置zookeeper的日志存放目录 ZOO_MY_ID 配置zookeeper的节点ID,和ZOO_SERVERS中的一一对应 ZOO_SERVERS 配置集群节点信息 # Kafka docker参数 ================================================== KAFKA_BROKER_ID 配置broker id KAFKA_PORT 配置服务端口 KAFKA_HEAP_OPTS 配置JVM heap内存限制 KAFKA_HOST_NAME 服务监听地址 KAFKA_ADVERTISED_HOST_NAME 同上 KAFKA_LOG_DIRS 配置数据存放分区 KAFKA_ZOOKEEPER_CONNECT 配置zookeeper连接 KAFKA_NUM_PARTITIONS 配置topics默认的Partition数量 KAFKA_DEFAULT_REPLICATION_FACTOR 配置topics的默认副本数 KAFKA_LOG_RETENTION_HOURS 配置Partition过期时间(小时) # 系统参数 ================================================== vm.max_map_count 定义了一个进程能拥有的最多的内存区域 vm.swappiness 配置是否允许使用swap虚拟内存 # ES参数 ================================================== iyunwei 纳尼?嗯,这只是我们爱运维的体现^_^ ES_JAVA_OPTS 配置ES JVM heap内存限制 cluster.name 集群名称 node.name 节点名称 node.master 节点角色配置,true表示可以成为主节点,false不能成为主节点 node.data 节点角色配置,true表示可以成为数据节点,false不能成为数据节点 node.ingest 节点角色配置,true表示可以成为协调节点,false不能成为协调节点(简单解释,请以官方为准) node.attr.rack 节点服务器所在的机柜信息,可能在数据分布中起到指导作用 discovery.zen.ping.unicast.hosts 配置自动发现IP列表 discovery.zen.minimum_master_nodes 防止脑裂,这个参数控制的是,一个节点需要看到的具有master节点资格的最小数量,然后才能在集群中做操作。官方的推荐值是(N/2)+1,其中N是具有master资格的节点的数量(我们的情况是3,因此这个参数设置为2,但对于只有2个节点的情况,设置为2就有些问题了,一个节点DOWN掉后,你肯定连不上2台服务器了,这点需要注意)。 gateway.recover_after_nodes 控制集群在达到多少个节点之后才会开始数据恢复,通过这个设置可以避免集群自动相互发现的初期,shard分片不全的问题,假如es集群内一共有5个节点,就可以设置为5,那么这个集群必须有5个节点启动后才会开始数据分片,如果设置为3,就有可能另外两个节点没存储数据分片 network.host 绑定服务的IP地址 transport.tcp.port 内部通信端口 http.port 对外服务端口 path.data 数据存放目录 bootstrap.memory_lock 锁住内存,确保ES不使用swap bootstrap.system_call_filter 系统调用过滤器,建议禁用该项检查,因为很多检查项需要Linux 3.5以上的内核,否则会报错。 # kibana参数 ================================================== SERVER_NAME 节点名称,可显示在X-pack界面 ELASTICSEARCH_URL 指定ES地址 ELASTICSEARCH_USERNAME ES鉴权用户,若ES开启了X-pack鉴权,则需要配置 ELASTICSEARCH_PASSWORD ES鉴权密码,同上 XPACK_MONITORING_UI_CONTAINER_ELASTICSEARCH_ENABLED 让x-pack支持docker的CPU使用率显示
本文涉及的部分参数简单解释(更多详细解释请咨询搜索引擎):
二、Docker 资源
1、Docker 私有仓库搭建(针对内网环境)
①、在有外网的服务器 192.168.1.111 上进行如下操作:
#安装docker yum install -y docker systemctl start docker #拉取私有仓库镜像: docker pull registry #启动仓库 docker run \ --restart=always \ --net=host \ -v /data/images:/tmp/registry \ -dti registry
Ps:若内部没有外网服务器,可以使用离线导出导入(save/load)的方案来做本地仓库,具体参考我之前整理的 Docker 入门教程-->传送门
②、docker 启动后,开始拉取所需镜像:
以下镜像均位于 dockerHub,拉取龟速,这里可以使用阿里云的 dockerHub 加速服务(腾讯云的仅支持腾讯云服务器内网使用)
zookeeper
镜像主页:https://hub.docker.com/_/zookeeper/
# 拉取 docker pull zookeeper # 推送本地仓库 docker tag zookeeper localhost:5000/zookeeper:latest docker push localhost:5000/zookeeper:latest
kafka
镜像主页: https://hub.docker.com/r/wurstmeister/kafka/
# 拉取 docker pull wurstmeister/kafka # 推送本地仓库 docker tag wurstmeister/kafka:latest localhost:5000/kafka:latest docker push localhost:5000/kafka:latest
Elastic
镜像主页:https://www.docker.elastic.co/
# 拉取 docker pull docker.elastic.co/elasticsearch/elasticsearch:5.6.8 docker pull docker.elastic.co/kibana/kibana:5.6.8 docker pull docker.elastic.co/logstash/logstash:5.6.8 # 打tag docker tag docker.elastic.co/elasticsearch/elasticsearch:5.6.8 localhost:5000/elastic/elasticsearch:5.6.8 docker tag docker.elastic.co/kibana/kibana:5.6.8 localhost:5000/elastic/kibana:5.6.8 docker tag docker.elastic.co/logstash/logstash:5.6.8 localhost:5000/elastic/logstash:5.6.8 # 推送本地仓库 docker push localhost:5000/elastic/elasticsearch:5.6.8 docker push localhost:5000/elastic/kibana:5.6.8 docker push localhost:5000/elastic/logstash:5.6.8
Ps:6.X 版本强制启用了 content-type 头部请求,比较烦,本文选择 5.X 的最后一个版本,实际使用请自行抉择。
完成以上步骤,我们就在 192.168.1.111 上建立了一个 Docker 私有仓库,地址是 192.168.1.111:5000。
2、所有服务器节点都安装要 docker,并开启私有仓库支持
yum install docker -y
vim /etc/sysconfig/docker 添加兼容私有仓库非 https 协议配置:
OPTIONS='--insecure-registry 192.168.1.111:5000'
启动 Docker:
systemctl start docker systemctl enable docker
完成这一步之后,Docker 环境已准备完毕。
三、部署 Kafka 集群
Ps:若只是单纯部署 ES 集群,而不需要用到 kafka,可以跳过本步骤
1、部署 zookeeper
①、部署节点 1
# 192.168.1.100 # 创建数据存放目录 mkdir -p /data/zookeeper # 启动 docker run --name zookeeper \ --net=host \ --restart always \ -v /data/zookeeper:/data/zookeeper \ -e ZOO_PORT=2181 \ -e ZOO_DATA_DIR=/data/zookeeper/data \ -e ZOO_DATA_LOG_DIR=/data/zookeeper/logs \ -e ZOO_MY_ID=1 \ -e ZOO_SERVERS="server.1=192.168.1.100:2888:3888 server.2=192.168.1.101:2888:3888 server.3=192.168.1.102:2888:3888" \ -d 192.168.1.111:5000/zookeeper:latest
②、部署节点 2
# 192.168.1.101 # 创建数据存放目录 mkdir -p /data/zookeeper # 启动 docker run --name zookeeper \ --net=host --restart always \ -v /data/zookeeper:/data/zookeeper \ -e ZOO_PORT=2181 \ -e ZOO_DATA_DIR=/data/zookeeper/data \ -e ZOO_DATA_LOG_DIR=/data/zookeeper/logs \ -e ZOO_MY_ID=2 \ -e ZOO_SERVERS="server.1=192.168.1.100:2888:3888 server.2=192.168.1.101:2888:3888 server.3=192.168.1.102:2888:3888" \ -d 192.168.1.111:5000/zookeeper:latest
③、部署节点 3
# 192.168.1.103 # 创建数据存放目录 mkdir -p /data/zookeeper # 启动 docker run --name zookeeper \ --net=host \ --restart always \ -v /data/zookeeper:/data/zookeeper \ -e ZOO_PORT=2181 \ -e ZOO_DATA_DIR=/data/zookeeper/data \ -e ZOO_DATA_LOG_DIR=/data/zookeeper/logs \ -e ZOO_MY_ID=3 \ -e ZOO_SERVERS="server.1=192.168.1.100:2888:3888 server.2=192.168.1.101:2888:3888 server.3=192.168.1.102:2888:3888" \ -d 192.168.1.111:5000/zookeeper:latest
2、部署 kafka
①、部署节点 1
# 机器有11块盘,这里都用起来 mkdir -p /data{1..11}/kafka # 启动 docker run --name kafka \ --net=host \ --volume /data1:/data1 \ --volume /data2:/data2 \ --volume /data3:/data3 \ --volume /data4:/data4 \ --volume /data5:/data5 \ --volume /data6:/data6 \ --volume /data7:/data7 \ --volume /data8:/data8 \ --volume /data9:/data9 \ --volume /data10:/data10 \ --volume /data11:/data11 \ -e KAFKA_BROKER_ID=1 \ -e KAFKA_PORT=9092 \ -e KAFKA_HEAP_OPTS="-Xms8g -Xmx8g" \ -e KAFKA_HOST_NAME=192.168.1.100 \ -e KAFKA_ADVERTISED_HOST_NAME=192.168.1.100 \ -e KAFKA_LOG_DIRS=/data1/kafka,/data2/kafka,/data3/kafka,/data4/kafka,/data5/kafka,/data6/kafka,/data7/kafka,/data8/kafka,/data9/kafka,/data10/kafka,/data11/kafka \ -e KAFKA_ZOOKEEPER_CONNECT="192.168.1.100:2181,192.168.1.101:2181,192.168.1.102:2181" \ -e KAFKA_NUM_PARTITIONS=10 \ -e KAFKA_DEFAULT_REPLICATION_FACTOR=2 \ -e KAFKA_LOG_RETENTION_HOURS=366 \ -d 192.168.1.111:5000/kafka:latest
②、部署节点 2
只需要修改如下参数,其他和节点 1 代码一样:
-e KAFKA_BROKER_ID=2 \ -e KAFKA_HOST_NAME=192.168.1.101 \ -e KAFKA_ADVERTISED_HOST_NAME=192.168.1.101 \
③、部署节点 3
同上所述,只需要修改如下参数:
-e KAFKA_BROKER_ID=3 \ -e KAFKA_HOST_NAME=192.168.1.102 \ -e KAFKA_ADVERTISED_HOST_NAME=192.168.1.102 \
完成之后,我们就使用纯 Docker 搭建了一个 Kafka 集群。
四、部署 ES 集群
1、内核参数优化
vim /etc/sysctl.conf
vm.max_map_count = 655360 vm.swappiness = 1
最后,执行 sysctl -p 生效
3、创建挂载目录
Master 节点:
mkdir -p /data/iyunwei/master chown -R 1000:1000 /data/iyunwei
Client 节点:
mkdir -p /data/iyunwei/client chown -R 1000:1000 /data/iyunwei
data 节点(TS 机器有 12 块盘,这里都用起来):
mkdir -p /data{1..12}/iyunwei/data chown -R 1000:1000 /data{1..12}/iyunwei
Ps:ES 官方 Docker 镜像启动用户 ID 是 1000,所以这里给 1000:1000 授权。
5、启动 Master、Client 和 DATA 节点
在 3 台 Master 节点执行如下启动脚本,其中只需要修改 node.name 值,比如 MASTER-100:
#!/bin/bash # 删除已退出的同名容器 docker ps -a | grep es_master |egrep "Exited|Created" | awk '{print $1}'|xargs -i% docker rm -f % 2>/dev/null # 启动 docker run --name es_master \ -d --net=host \ --restart=always \ --privileged=true \ --ulimit nofile=655350 \ --ulimit memlock=-1 \ --memory=12G \ --memory-swap=-1 \ --cpuset-cpus='31-34' \ --volume /data:/data \ --volume /etc/localtime:/etc/localtime \ -e TERM=dumb \ -e ES_JAVA_OPTS="-Xms8g -Xmx8g" \ -e cluster.name="iyunwei" \ -e node.name="MASTER-100" \ -e node.master=true \ -e node.data=false \ -e node.ingest=false \ -e node.attr.rack="0402-K03" \ -e discovery.zen.ping.unicast.hosts="192.168.2.100:9301,192.168.2.101:9301,192.168.2.102:9301,192.168.2.100:9300,192.168.2.102:9300,192.168.2.103:9300,192.168.3.100:9300,192.168.3.101:9300,192.168.3.102:9300,192.168.3.103:9300" \ -e discovery.zen.minimum_master_nodes=2 \ -e gateway.recover_after_nodes=5 \ -e network.host=0.0.0.0 \ -e transport.tcp.port=9301 \ -e http.port=9201 \ -e path.data="/data/iyunwei/master" \ -e path.logs=/data/elastic/logs \ -e bootstrap.memory_lock=true \ -e bootstrap.system_call_filter=false \ -e indices.fielddata.cache.size="25%" \ 192.168.1.111:5000/elastic/elasticsearch:5.6.8
在 3 台 Client 节点启动如下脚本,同样只需要修改 node.name 的值,比如 CLIENT-101:
#!/bin/bash docker ps -a | grep es_client |egrep "Exited|Created" | awk '{print $1}'|xargs -i% docker rm -f % 2>/dev/null docker run --name es_client \ -d --net=host \ --restart=always \ --privileged=true \ --ulimit nofile=655350 \ --ulimit memlock=-1 \ --memory=64G \ --memory-swap=-1 \ --cpuset-cpus='23-30' \ --volume /data:/data \ --volume /etc/localtime:/etc/localtime \ -e TERM=dumb \ -e ES_JAVA_OPTS="-Xms31g -Xmx31g" \ -e cluster.name="iyunwei" \ -e node.name="CLIENT-100" \ -e node.master=false \ -e node.data=false \ -e node.attr.rack="0402-K03" \ -e discovery.zen.ping.unicast.hosts="192.168.2.100:9301,192.168.2.101:9301,192.168.2.102:9301,192.168.2.100:9300,192.168.2.102:9300,192.168.2.103:9300,192.168.3.100:9300,192.168.3.101:9300,192.168.3.102:9300,192.168.3.103:9300" \ -e discovery.zen.minimum_master_nodes=2 \ -e gateway.recover_after_nodes=2 \ -e network.host=0.0.0.0 \ -e transport.tcp.port=9300 \ -e http.port=9200 \ -e path.data="/data/iyunwei/client" \ -e path.logs=/data/elastic/logs \ -e bootstrap.memory_lock=true \ -e bootstrap.system_call_filter=false \ -e indices.fielddata.cache.size="25%" \ 192.168.1.111:5000/elastic/elasticsearch:5.6.8
在4台 DATA 节点启动如下脚本,同样只需要修改 node.name 的值,比如 DATA-101:
#!/bin/bash docker ps -a | grep es_data |egrep "Exited|Created" | awk '{print $1}'|xargs -i% docker rm -f % 2>/dev/null docker run --name es_data \ -d --net=host \ --restart=always \ --privileged \ --ulimit nofile=655350 \ --ulimit memlock=-1 \ --volume /data:/data \ --volume /data1:/data1 \ --volume /data2:/data2 \ --volume /data3:/data3 \ --volume /data4:/data4 \ --volume /data5:/data5 \ --volume /data6:/data6 \ --volume /data7:/data7 \ --volume /data8:/data8 \ --volume /data9:/data9 \ --volume /data10:/data10 \ --volume /data11:/data11 \ --volume /etc/localtime:/etc/localtime \ --ulimit memlock=-1 \ -e TERM=dumb \ -e ES_JAVA_OPTS="-Xms31g -Xmx31g" \ -e cluster.name="iyunwei" \ -e node.name="DATA-135" \ -e node.master=false \ -e node.data=true \ -e node.ingest=false \ -e node.attr.rack="0402-Q06" \ -e discovery.zen.ping.unicast.hosts="192.168.2.100:9301,192.168.2.101:9301,192.168.2.102:9301,192.168.2.100:9300,192.168.2.102:9300,192.168.2.103:9300,192.168.3.100:9300,192.168.3.101:9300,192.168.3.102:9300,192.168.3.103:9300" \ -e discovery.zen.minimum_master_nodes=2 \ -e gateway.recover_after_nodes=2 \ -e network.host=0.0.0.0 \ -e http.port=9200 \ -e path.data="/data1/iyunwei/data,/data2/iyunwei/data,/data3/iyunwei/data,/data4/iyunwei/data,/data5/iyunwei/data,/data6/iyunwei/data,/data7/iyunwei/data,/data8/iyunwei/data,/data9/iyunwei/data,/data10/iyunwei/data,/data11/iyunwei/data,/data12/iyunwei/data" \ -e path.logs=/data/elastic/logs \ -e bootstrap.memory_lock=true \ -e bootstrap.system_call_filter=false \ -e indices.fielddata.cache.size="25%" \ 192.168.1.111:5000/elastic/elasticsearch:5.6.8
6、注册 x-pack
官方镜像都默认集成了 x-pack,x-pack 是 elastic 官方的商业版插件,支持监控、鉴权以及机器学习等功能。
坏消息是这玩意按节点收费,一个节点 6 万/年,比较昂贵!
好消息是我们可以免费使用 x-pack 的基础版本(1 年授权,可更换),支持集群可视化监控,导入授权后 x-pack 会自动关闭 monitoring 以外的功能,比如登陆鉴权等【
套餐详情】。
注册步骤:
①、注册并下载授权码:https://register.elastic.co/xpack_register
,得到类似 jager-zhang-d13eeec2-723c-41d2-b912-4c56674c32a0-v5.json 授权文件
②、导入授权信息:
教程:
https://www.elastic.co/guide/en/x-pack/current/license-management.html
curl -XPUT http://192.168.2.100:9200/_license?acknowledge=true -d @jager-zhang-d13eeec2-723c-41d2-b912-4c56674c32a0-v5.json -uelastic:changeme
这样就激活了 x-pack 了。
7、部署 kibana
#!/bin/bash docker ps -a | grep kibana | egrep "Exited|Create" | awk '{print $1}'|xargs -i% docker rm -f % 2>/dev/null docker run --name kibana \ --restart=always \ -d --net=host \ -v /data:/data \ -v /etc/localtime:/etc/localtime \ --privileged \ -e TERM=dumb \ -e SERVER_HOST=0.0.0.0 \ -e SERVER_PORT=5601 \ -e SERVER_NAME=Kibana-100 \ -e ELASTICSEARCH_URL=http://localhost:9200 \ -e ELASTICSEARCH_USERNAME=elastic \ -e ELASTICSEARCH_PASSWORD=changeme \ -e XPACK_MONITORING_UI_CONTAINER_ELASTICSEARCH_ENABLED=false \ -e LOG_FILE=/data/elastic/logs/kibana.log \ 192.168.1.111:5000/elastic/kibana:5.6.8
Ps:XPACK_MONITORING_UI_CONTAINER_ELASTICSEARCH_ENABLED 这个参数还有一个折腾记录,回头补上分享。
8、部署 logstash
logstash 在整个架构中属于消费者角色,将数据从 kafka 中读出,然后写入 ES。
#!/bin/bash docker ps -a | grep logstash |egrep "Exited|Created" | awk '{print $1}'|xargs -i% docker rm -f % 2>/dev/null docker run --name logstash \ -d --net=host \ --restart=always \ --privileged \ --ulimit nofile=655350 \ --ulimit memlock=-1 \ -e ES_JAVA_OPTS="-Xms16g -Xmx16g" \ -e TERM=dumb \ --volume /etc/localtime:/etc/localtime \ --volume /data/elastic/config:/usr/share/logstash/config \ --volume /data/elastic/config/pipeline:/usr/share/logstash/pipeline \ --volume /data/elastic/logs:/usr/share/logstash/logs \ 192.168.1.111:5000/elastic/logstash:5.6.8
Ps:/data/elastic/config 存放了 logstash 配置文件,其中 pipeline 文件夹里面存放 logstash 的 input、filter、output 规则。logstash.yml 是主配置文件,如下是推荐配置项:
# 名称,会在x-pack展示 node.name: LOGSTASH-100 # 配置文件夹目录 path.config: /usr/share/logstash/pipeline # 配置ES地址,用于上报自我监控信息到ES xpack.monitoring.elasticsearch.url: http://localhost:9200 # 自动重载配置(很赞) config.reload.automatic: true # 每60秒检查配置是否有修改(很赞) config.reload.interval: 60
Ps:本文附件可以下载到完整的 config 配置文件。
10、拓展配置
由于我们使用的是 x-pack 的基础版本,所以没有鉴权功能,这里只好折中处理一下:
- 引入 Aproxy 对 kibana 做鉴权(部署文档)
- 使用 iptables 对端口做安全限制,只允许指定机器访问相关端口,比如:
iptables -I INPUT -p tcp -m multiport --dports 9200,9300,9201,9301,5601 -j REJECT --reject-with icmp-port-unreachable iptables -I INPUT -s 192.168.1.100/32 -p tcp -m multiport --dports 9200,9300,9201,9301,5601 -j ACCEPT iptables -I INPUT -s 192.168.1.101/32 -p tcp -m multiport --dports 9200,9300,9201,9301,5601 -j ACCEPT iptables -I INPUT -s 192.168.1.102/32 -p tcp -m multiport --dports 9200,9300,9201,9301,5601 -j ACCEPT iptables -I INPUT -s 192.168.2.100/32 -p tcp -m multiport --dports 9200,9300,9201,9301,5601 -j ACCEPT iptables -I INPUT -s 192.168.2.101/32 -p tcp -m multiport --dports 9200,9300,9201,9301,5601 -j ACCEPT iptables -I INPUT -s 192.168.2.102/32 -p tcp -m multiport --dports 9200,9300,9201,9301,5601 -j ACCEPT iptables -I INPUT -s 192.168.3.101/32 -p tcp -m multiport --dports 9200,9300,9201,9301,5601 -j ACCEPT iptables -I INPUT -s 192.168.3.102/32 -p tcp -m multiport --dports 9200,9300,9201,9301,5601 -j ACCEPT iptables -I INPUT -s 192.168.3.103/32 -p tcp -m multiport --dports 9200,9300,9201,9301,5601 -j ACCEPT iptables -I INPUT -s 192.168.3.104/32 -p tcp -m multiport --dports 9200,9300,9201,9301,5601 -j ACCEPT iptables -I INPUT -s 127.0.0.1/32 -p tcp -m multiport --dports 9200,9300,9201,9301,5601 -j ACCEPT
五、成品展示
全部完成之后,访问 kibana 地址就能看到漂亮的界面啦!当然,真正数据上报之前,我们还需要做一些准备工作,比如添加索引模板等,本文篇幅有限这里就不做更多介绍了,敬请关注张戈博客 ES 系列文集(整理中)!
下面截 2 张美图,诱惑一下,喜欢的话赶紧折腾吧!
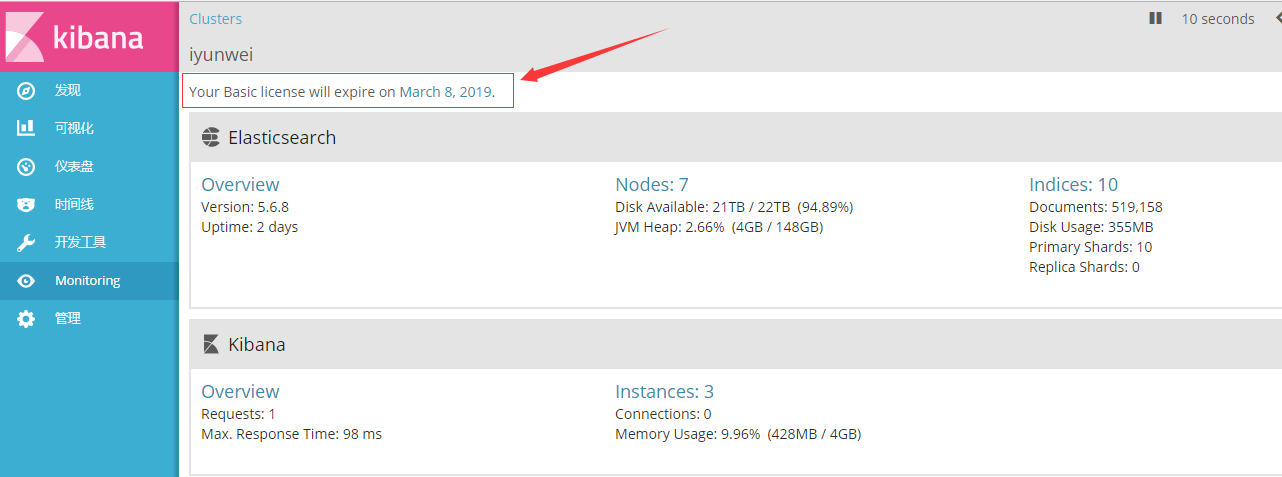
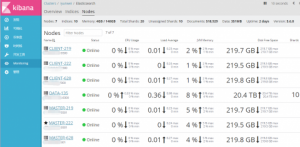
Ps:因为是预发布时截图的,节点信息不全,请忽略里面的具体数据信息。另外,Kibana 的汉化教程下次整理分享,敬请期待!
- 安卓客户端下载
- 微信扫一扫
-

- 微信公众号
- 微信公众号扫一扫
-