- A+
一、什么是高可用
高可用HA(High Availabilty),通常来描述一个服务避免服务中断,而保持其服务的高度可用性。如,交换机、负载均衡、存储、队列、缓存等
HA通常有三种工作方式
(1)主从方式
工作原理:主机与备机通过心跳检测,当主机宕机时,备机接管主机的一切工作,待主机恢复正常后,按使用者的设定以自动或手动方式将服务切换到主机上运行,目前互联网用到的最多的高可用开源软件最多的是keepalived和heartbeat,这两个用的都挺多
(2)双主工作方式
工作原理:两台主机同时运行各自的服务工作且相互监测情况,当任一台主机宕机时,另一台主机立即接管它的一切工作,保证工作实时,应用服务系统的关键数据存放在共享存储系统中。(rabbitmq等)
(3)群集工作方式
工作原理:多台主机一起工作,各自运行一个或几个服务,各为服务定义一个或多个备用主机,当某个主机故障时,运行在其上的服务就可以被其它主机接管。(hadoop/elastic等)
二、系统高可用设计
目前来说,凡是对外提供服务的系统,几乎没有单点了,毕竟硬件资源越来越便宜了,也不在乎成本的问题了,毕竟数据可靠性才最重要的,保障系统高可用,系统冗余已经是每个架构师设计系统的基本必备,即使架构师忽略这一点,运维人员也会通过第三方软件确保系统稳定性,接下来我们看看互联网是怎么做的
三、常见的互联网分层架构
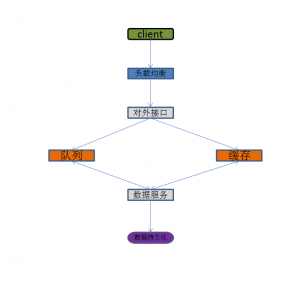
上图是互联网最常见的互联网分布式架构,分为:
(1)客户端:通常是浏览器,手机系统,手机app等
(2)负载均衡:反向代理,流量均衡
(3)对外接口:对外提供业务逻辑服务
(4)数据服务:数据传输、处理操作
(5)缓存:加速数据查询,提高访问速度
(6)队列:缓冲大并发数据
(7)数据持久化:数据固化存储
整个系统服务架构都需要高可用,每一层又通过冗余+自动故障转移来避免单点
四、分层高可用架构实践
负载均衡的高可用
首先说一下负载均衡吧,通用到的为七层代理的nginx和四层(目前商业版也支持七层)的lvs.还有业务的用到的同时支持四、七层的haproxy,一般web类应用接口我们通常通过nginx代理;rpc或者xmpp之类协议接口,大多直接用lvs。当然web类也有用lvs+nginx,这里lvs就不单单是做负载均衡了,还会用来做nat。
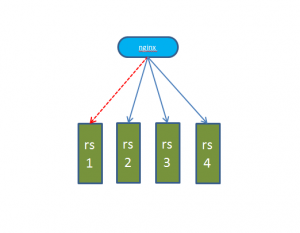
不管是lvs还是nginx,负载均衡的高可用大多数都是主从模式,如下图:

如上图,负载均衡备机通过配置keeplived或者heartbeat对负载均衡主定时进行心跳检测,当发现主机异常时,会自动切换到备机。这里要说的是负载均衡对外提供的是服务器虚出来的ip,不然切换过去ip变了,还得手动修改域名解析。
对外接口的高可用
其实这一块确保高可用做法挺多的,我们这里举例说一种吧,就是通过nginx代理的web服务,一般情况下,稍微有些并发的业务,都是同时部署多个实例,然后通过nginx(或其他软件)代理,nginx自带了一个插件nginx_upstream_check_module-maste,当发现后端有down的rs,就会自动摘除该rs
缓存、队列的高可用
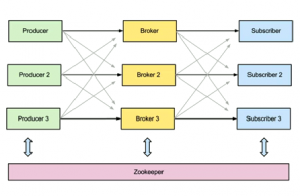
队列通常有rabbitmq、kafka等;rabbitmq的精度比kafka高,但是吞吐量不如kafka,rabbitmq的高可用是借助于erlang语言特性,把需要的队列做成镜像队列,存在于多个节点,然后前端通过负载均衡实现;kafka则是借助于zk来实现的,如图:
缓存通常有redis和memcached,redis自带ha就不再多说了,memcached目前有一个管理工具但是不常用,用代理的话,数据一致性又比较麻烦,所以尽量最少故障,一般对key进行分片存储
数据服务高可用
当数据量大的时候,我们就得对数据库进行分表分库,这时我们就会把数据层单独抽出来,通过haproxy(lvs针对于这个场景不是太合适,ip绑定的太多)代理,类似于nginx代理对外接口
数据持久化
数据持久化的存储工具现在不少,互联网通常用的较多的hbase,mongo,mysql等。hbase就不说了,底层hadoop支撑,nongo也有自带的高可用方式,mysql要不就cluster,要不就通过keeplived来检测心跳,同时数据实时同步到备库
五、总结
高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。
方法论上,高可用是通过冗余+自动故障转移来实现的。
整个互联网分层系统架构的高可用,又是通过每一层的冗余+自动故障转移来综合实现的,具体的:
(1)【客户端层】到【反向代理层】的高可用,是通过反向代理层的冗余实现的,常见实践是keepalived + virtual IP自动故障转移
(2)【反向代理层】到【站点层】的高可用,是通过站点层的冗余实现的,常见实践是nginx与web-server之间的存活性探测与自动故障转移
(3)【站点层】到【服务层】的高可用,是通过服务层的冗余实现的,常见实践是通过service-connection-pool来保证自动故障转移
(4)【服务层】到【缓存层】的高可用,是通过缓存数据的冗余实现的,常见实践是缓存客户端双读双写,或者利用缓存集群的主从数据同步与sentinel保活与自动故障转移;更多的业务场景,对缓存没有高可用要求,可以使用缓存服务化来对调用方屏蔽底层复杂性
(5)【服务层】到【数据库“读”】的高可用,是通过读库的冗余实现的,常见实践是通过db-connection-pool来保证自动故障转移
(6)【服务层】到【数据库“写”】的高可用,是通过写库的冗余实现的,常见实践是keepalived + virtual IP自动故障转移
- 安卓客户端下载
- 微信扫一扫
-

- 微信公众号
- 微信公众号扫一扫
-