- A+
IPFS简介
本篇文章主要想通过纯理论的方式分析IPFS的原理,尽量不使用命令和代码。关于IPFS的诞生以及取代HTTP的可能性分析,已经有太多大神写过文章了,这里就不再赘述了。感兴趣的前往这里了解 http://ipfser.org、以及IPFS白皮书。
一、 什么是IPFS
IPFS, 星际文件系统 ( InterPlanetary File System )。2014年开始由Protocol Labs (协议实验室)在开源社区的帮助下发展。其最初由Juan Benet设计。是一个旨在创建持久且分布式存储和共享文件的网络传输协议。是永久的、去中心化保存和共享文件的方法,这是一种内容可寻址、版本化、点对点超媒体的分布式协议。
内容可寻址:通过文件内容生成唯一哈希值来标识文件,而不是通过文件保存位置来标识。相同内容的文件在系统中只会存在一份,节约存储空间版本化:可追溯文件修改历史点对点超媒体:P2P 保存各种各样类型的数据可以把 IPFS 想象成所有文件数据是在同一个 BitTorrent 群并且通过同一个 Git 仓库存取。
二、 IPFS的存储与读取
接下来先基础地介绍下IPFS是怎么进行存储和读取的。IPFS文件的存储和读取与BitTorrent上传下载原理相似。IPFS采用的索引结构是DHT(分布式哈希表),数据结构是Merkle DAG(Merkle 有向无环图)。
2.1 单文件存储
研究过文件系统的人都知道索引和扇区这两个概念,如:NTFS一个扇区通常是4K,真正的文件数据都是保存在扇区里面的,找到这些扇区的方式就是建立索引(确切的说是高效的索引),IPFS也是一个文件系统,不同的是,IPFS是没有存储上限的,且不存在空间回收的功能。IPFS存储文件时,如图(没天赋,略丑),会经历以下几个步骤:
1. 把单个文件拆分成若干个256KB大小的块( block,这个就可以理解成扇区 );
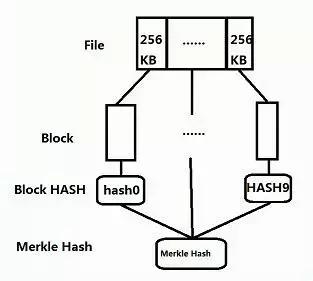
2. 逐块(block)计算block hash,hashn = hash ( blockn );
3. 把所有的block hash拼凑成一个数组,再计算一次hash,便得到了文件最终的hash,hash ( file ) = hash ( hash1……n ),并将这个 hash(file) 和block hash数组“捆绑”起来,组成一个对象,把这个对象当做一个索引结构;
4. 把block、索引结构全部上传给IPFS节点(这里先不介绍细节),文件便同步到了IPFS网络了;
5. 把 Hash(file)打印出来,读的时候用;PS: 这里可以看出IPFS计算文件得到的hash,其实和我们平时计算hash的方式不一样,而且最终的结果也不一样!
这里还漏掉了一个小文件的处理逻辑,和NTFS等文件系统类似,小文件(小于 1KB) 的文件,IPFS会把数据内容直接和Hash(索引)放在一起上传给IPFS节点,不会再额外的占用一个block的大小。现在,已经把文件的原始数据和文件的索引(即hash)上传到IPFS网络了。前面已经讲过,IPFS是不支持空间回收的,文件一旦同步到IPFS,将永久的存在。看起来这样会招来一个严重的后果就是,如果频繁的编辑大文件,每编辑一次就要重新同步,岂不是会过度浪费空间!?
举个例子:本地有一个1G的大文件File1,已经同步到IPFS了,后面在这个文件File1后面追加了1K的内容,现在需要重新同步这个文件,算下来需要花费的空间应该是:1G+1G+1K;然而,事实并非如此。IPFS在储存数据的时候,同一份数据只存储一次,文件是分块(block)存储的,hash相同的block,只会存储一次,也就说,前面1G的内容没有发生改变,其实IPFS并不会为这些数据分配新的空间,只会为最后1K的数据分配一个新的block,再重新上传hash,实际占用的空间是: 1G + 1K ;
不同的文件有很多数据是存在重复的,如不同语言字幕的电影,影音部分相同的,只有字幕部分不一样,当两个不同国家的人都在上传同一部电影的时候,这些文件在分块(block)的时候,很有可能有大部分block的hash是一致的,这些block在IPFS上也只会存储一份,这样一来就可能会有很多文件的索引指向同一个block,这里就构成了前面提到的一个数据结构——Merkle DAG(Merkle 有向无环图)。下面盗个图,形象的说明下DAG是个什么东东。
因为所有的索引上都保存了hash,所以Merkle DAG具有以下特点(从白皮书上扒下来的):1. 内容可寻址:所有内容都是被多重hash校验和来唯一识别的,包括links。2. 无法篡改:所有的内容都用它的校验和来验证。如果数据被篡改或损坏,IPFS会检测到。3. 重复数据删除:重复内容并只存储一次。
2.2 文件树存储
IPFS支持目录结构,存储目录的方式很简单:
1. 先把目录下所有的文件同步到IPFS网络中去,为所有的文件hash建立一个别名,这个别名其实就是本地文件名,把hash和别名“捆绑”在一起组建成一个名为 IPFSLink 的对象;
2. 把该目录下所有的 IPFSLink 对象组成一个数组,对该数组计算一个目录hash,并将数组和目录hash拼成一个结构体,同步到IPFS网络;
3. 如果上层还有目录结构,则为目录hash建立一个别名(就是目录名),把目录hash和别名“捆绑”在一起组建成一个 IPFSLink 的对象,重复从步骤2开始执行;
4. 把目录hash打印出来,读取的时候用;
由上可以看出,对于IPFS而言,存储目录和文件其实是一样的处理方式,IPFS甚至根本没有关心节点想要存储的是一个目录还是一个文件。
2.3 单文件读取
IPFS取文件的方式,就比较简单了,就是存储方式的一个逆推过程:
1. 根据hash搜索该hash的索引结构,即找到该文件hash 的 block hash数组(这一步由IPFS网络完成,是旷工该干的事情),下载下来;
2. 此时已经得到了 block 的索引,根据block hash,搜索block所在的节点位置,下载下来;
3. 本地拼装block:根据block hash数组的顺序,把文件拼凑好。
block的下载是IPFS的核心,这中间涉及到很多复杂的技术细节,因为个人能力有限,这里没有展开讨论,只是先一笔带过。希望不会误导新入门的读者,以为IPFS就只干了这么点事情!
2.4 文件树读取
目录的读取也是目录存储过程的逆推:
1. 根据hash搜索该hash的索引结构,找到该目录的 IPFSLink 对象数组,即目录下的子列表;
2. 遍历数组,如果IPFSLink对象是文件,则取出文件的hash下载该文件;
3. 如果IPFSLink对象是目录,取出目录hash,重新从步骤1开始执行;
三、 IPFS的未来
总的来说,IPFS具备很多良好的特性,如:自带高可用属性,不会宕机(除非全球停电或者断网)、抗DOS、防篡改……不需要购买昂贵的防火墙设备来做这些事情。其他的优点请自行去 ipfser.org get!
此文对你有帮助请点点关注!
- 安卓客户端下载
- 微信扫一扫
-

- 微信公众号
- 微信公众号扫一扫
-




