- A+
本文缘起于最近几天笔者实现的一段代码,目的是利用 python 在 Linux 中实现一个常驻内存的后台守护进程负责向其他进程提供服务,起初笔者自信的认为 multiprocessing.Process 类的 daemon 属性应该符合要求,于是乎不假思索的挥毫写下测试代码如下:
清单 1 永不消逝的进程 v0
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
from multiprocessing import Process
from time import sleep
def child_process():
# 子进程函数
# 建立一个进程,每隔一秒钟输出"child's still alive."
while (1):
print("child's still alive.")
sleep(1)
def main():
# 主进程函数
p = Process(target=child_process)
p.daemon = True # 设置 daemon 属性为 True
p.start()
sleep(10) # 休眠 10 秒后结束
print("Main process ends.")
print("Will child process live forever?") # 我们期待子进程继续活着,但事实上……
if __name__ == "__main__":
main()
|
这段程序的目的很简单:主进程(main())利用 Process 对象 fork 出一个子进程(child_process()),设上 daemon 属性,然后结束自己,期待着子进程可以就这么活下去,安静地每隔 1 秒输出一行"child's still alive"。
当然,如果运行结果如前所述的话,那笔者估计也不会作此拙作了。
实际的运行结果是:伴随着"will child process live forever?",子进程的输出也戛然而止,这意味着子进程最终也还是随着父进程的消亡而消逝了。
这个问题着实困扰了笔者一阵,直到在Process 文档中的 daemon 属性下看到了这句描述:
When a process exits, it attempts to terminate all of its daemonic child processes.
真相大白,原来这里的 daemon 并非真正意义上的守护进程,而是"守护父进程的进程",当父进程结束的时候,"守护着"它的进程也会被自动销毁。
于是,在感叹写程序切不可望文生义的同时,笔者也不得不开始琢磨如何自己动手丰衣足食,另辟蹊径来实现守护进程了。
所幸,在 Linux 下,想要实现出一个不死的进程,办法还是很多的。
从 nohup 说开去
开始这一部分正文之前,先说一小段题外话:若干年前,笔者刚刚才加工作之时,曾经参加过一款基于嵌入式 Linux 的模块的研发。如今回想起来,当时最为印象深刻的,就是这个模块的软件系统极其庞杂,限于开发服务器的性能,一次完整的编译,有时候竟需要半个小时甚至更久的时间。倘若有幸在临近下班时分下载一份全新的代码进行编译,那欲哭无泪的画面实在是美的令人不忍直视。
那时笔者尚属菜鸟,于是便数次毫无悬念地在 terminal 前面等待满长的编译结束直到华灯初上。直到有一天一位过路神仙给笔者支了个招:
nohup make &
关机!下班!
然后,等到笔者次日懵懵懂懂的回到办公室打开电脑,编译完毕的二进制文件早已安安静静的躺在服务器的硬盘里了。
——知识就是力量!
好,题外话告一段落,现在咱们来看一看这 nohup 的力量到底来自哪里:
解密 nohup
一般而言,man 命令是了解绝大部分 Linux 命令的绝佳入口,但是打开 nohup 的 man page,却只能发现寥寥数语:
nohup - run a command immune to hangups, with output to a non-tty
这样简略的信息只怕是不够我们理解其原理的,幸而 nohup 是 GNU Coreutil 的一部分,本着死代码不说谎的原则,笔者又寻到了源码,却发现其实现出人意料的简单(其实现摘要如清单 2 所示,中文注释为笔者所加):
清单 2 nohup.c
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
int
main (int argc, char **argv)
{
/* …… */
if (ignoring_input)
{
/* 重定向标准输入到/dev/null */
}
if (redirecting_stdout || (redirecting_stderr && stdout_is_closed))
{
/* 重定向标准输出到文件 */
}
if (redirecting_stderr)
{
/* 重定向标准错误到文件 */
}
/* 忽略 SIGHUP 信号 */
signal (SIGHUP, SIG_IGN);
/* 执行 cmd */
char **cmd = argv + optind;
execvp (*cmd, cmd);
/* …… */
return exit_status;
}
|
抛去一堆重定向带来的视觉杂讯,我们不难发现,在创建一个新的进程执行以参数形式传入的 cmd 之前(execvp),nohup 忽略了 SIGHUP 信号,这意味着,作为 nohup 子进程被执行的命令,如果其自身不做任何特殊处理(例如重新为 SIGHUP 信号绑定一个 handler),同样会继承其父进程对所有信号的处理方式,即对 SIGHUP 信号不闻不问。
结合从 man page 中得到的信息,我们很容易将"immune to hangups"和"signal (SIGHUP, SIG_IGN)"等同起来,但是,为什么忽略了 SIGHUP 信号的子进程就不会随着父进程的结束而消逝?在什么样的场景下,一个进程会收到 SIGHUP 信号呢?
要回答这个问题,我们首先要了解 Linux 系统中描述进程关系(Process Relationships)的两个非常重要的术语:进程组(Process Group)和会话(Session)。
进程组和会话
在开始枯燥的术语介绍之前,先让我们来看一看在一个真实的 Linux 环境下的进程组和会话到底长什么样:
清单 3 利用 ps -j 显示进程组和会话信息
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#首先远程 SSH 登陆一台 Linux 服务器
$ ssh zhang@9.115.241.18
#然后打开一个后台进程直接进入休眠
$ sleep 1000 &
[1] 23661 #这里的 23661 号进程就是我们的研究对象
#接下来我们利用 ps j 命令来查看一下当前 login shell 进程 ($$) 和 23661 进程的作业(job)相关信息
$ ps j 23661 $$
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
4721 21682 21682 21682 pts/20 23856 Ss 1000 0:00 -bash
21682 23661 23661 21682 pts/20 23856 S 1000 0:00 sleep 1000
#上表的返回值中,PID 指进程 id;PPID 指父进程 PID;PGID 指进程组 id
#SID 指会话 id;TTY 指会话的控制终端设备;COMMAND 指进程所执行的命令
#TPGID 指前台进程组的 PGID。
#由于当前掌握着控制终端的是 ps 进程,故上述两个进程的 TPGID 都为 23856。
|
由清单 3 最后的 ps 结果可以发现若干貌似巧合的结果,例如进程 23661 的 PGID 恰好等于 PID;又比如进程 23661(sleep 1000)和 21682(login shell 进程)共享同一个 SID(亦即 login shell 的 PID)。在接下来的内容里笔者将通过对进程组和会话的解读,向读者展示这些巧合的背后到底隐藏了怎么样的设计。
进程组和会话都是 Unix 早期被引入的概念,其中进程组的设计在早期 AT&T Unix 发行版中就已初见端倪;而会话则要略晚一些,其设计雏形直到 SVR4 才被引入。
本着先来后到的原则,笔者先来介绍进程组:
- 顾名思义,进程组就是一系列相互关联的进程集合,系统中的每一个进程也必须从属于某一个进程组;
- 每个进程组中都会有一个唯一的 ID(process group id),简称 PGID;PGID 一般等同于进程组的创建进程的 Process ID,而这个进进程一般也会被称为进程组先导(process group leader),同一进程组中除了进程组先导外的其他进程都是其子孙;
- 进程组的存在,方便了系统对多个相关进程执行某些统一的操作,例如,我们可以一次性发送一个信号量给同一进程组中的所有进程。
在早期 Unix 的设计中,进程组主要是用于终端访问控制(control terminal access)。以 SVR3 为例,一个比较典型的应用场景是:每当有一个终端通过某一 TTY 来访问服务器,一个包含了 login shell 进程的进程组就会被建立起来,因此进程组先导一般是为该终端而建的 shell 进程。当时还没有作业控制的概念,于是所有在该 shell 中被建立的新进程都会自动的隶属于同一进程组之下。同时该 tty 也会被设置为该进程组下所有进程共有的控制终端 (Controlling Terminal) ,所有的进程可以同时对控制终端进行读写。下图大致反映了当有终端用户接入时早期 Unix 环境下的进程布局:
图 1. 早期 Unix(SVR3)下的进程组设计
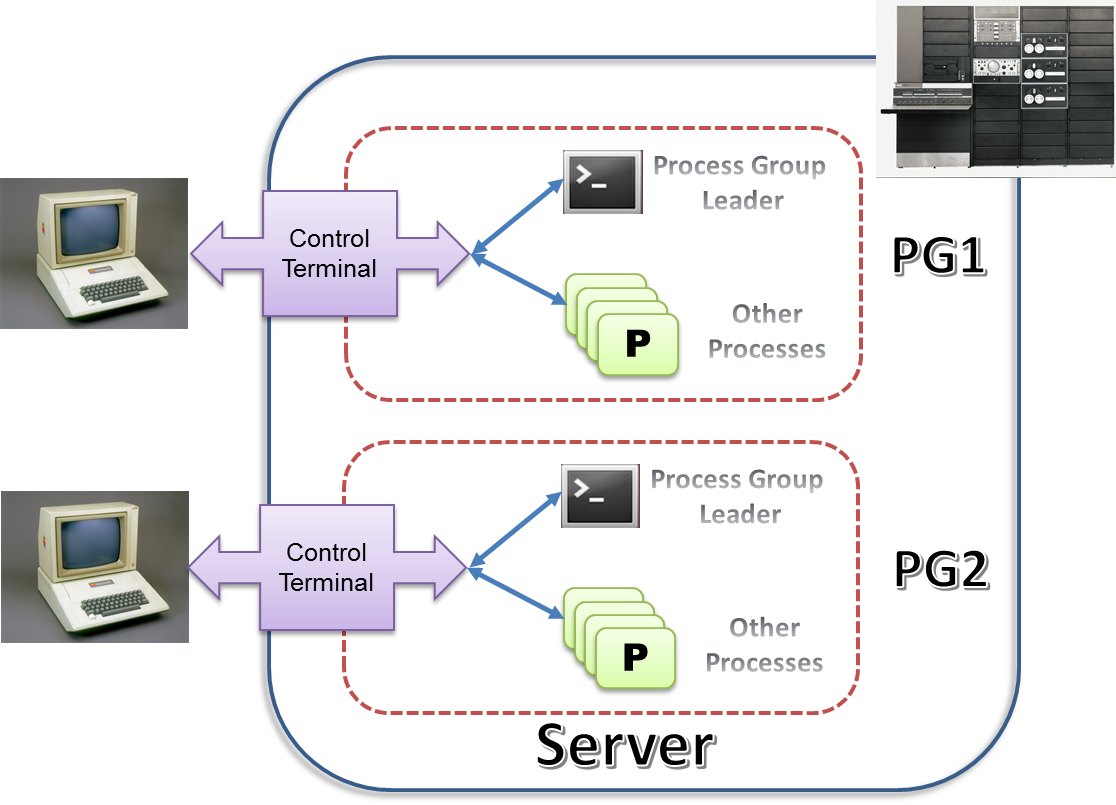
诚然,以事后诸葛亮的眼光来看,这样的设计是存在不少弊端的,比如进程组对控制终端缺乏有效的管理手段;再比如所有进程无差别共享控制终端的设计会带来灾难性的混乱。
于是在 SVR4 之后,作业控制(job control)的概念被提了出来,会话的设计也随即被引入了进来:
- 会话是一个若干进程组的集合,同样的,系统中每一个进程组也都必须从属于某一个会话;
- 一个会话只拥有最多一个控制终端(也可以没有),该终端为会话中所有进程组中的进程所共用。当然和早期设计中所有进程都可以无差别读写控制终端不同,这一次,进程被以进程组为单位划分为两类:前台进程组(foreground process group)和后台进程组(background process group)。一个会话中前台进程组只会有一个,只有其中的进程才可以和控制终端进行交互;除了前台进程组外的进程组,都是后台进程组;
- 和进程组先导类似,会话中也有会话先导(session leader)的概念,用来表示建立起到控制终端连接的进程。在拥有控制终端的会话中,session leader 也被称为控制进程(controlling process),一般来说控制进程也就是登入系统的 shell 进程(login shell);
- 为了支持作业控制,很多 shell 工具也做了相应的修改:在执行一个新的命令时,新生成的进程都会被置于一个和 Shell 进程不一样的全新的进程组之下;
一言以蔽之,新的设计将控制终端(tty 或 pty)的访问和控制完全置于了会话的管理之下,最大限度的避免了旧设计所带来的弊端。下图反映了在引入了会话的设计之后,有终端用户访问系统时进程的大致布局。
图 2. 进程组和会话

现在我们再来回顾一下清单 3 中的那些"巧合":
- 在 login shell 进程(PID=21682)被创建出来的同时,一个新的会话(SID=21682)和新的进程组(PGID=21682) 也同时被创建了出来,会话的控制进程(或会话先导)即 login shell 进程本身,控制终端是 pts/20;
- 当 sleep 进程(PID=23661)被创建出来的同时,新的进程组(PGID=23661)也同时被创建了起来,进程组被置于后台运行(命令行末尾有&)。由于隶属于会话 21682,所以该进程组的控制终端也是 pts/20;
大致搞清了进程组和会话之后,现在我们再回到最初的那个问题:信号 SIGHUP 在这一设计体系下到底扮演了什么角色?
SIGHUP,如其字面所述,这是一个用来描述 "挂断" 状态的信号,也就是说,当终端连接被关闭或无法维系之时,就需要这个信号出场了。具体来讲,每当:
- 终端连接中断时,SIGHUP 会被发送到控制进程,后者会在将这个信号转发给会话中所有的进程组之后自行了断;
- 控制进程被关闭时,SIGHUP 会被直接发送给会话中所有的进程组;
顺便说一句,一般进程对于 SIGHUP 信号的默认处理也同样是终结自己。
这样一来,笔者当年的困惑就被解答了:用于编译的 make 程序没有对 SIGHUP 信号做任何特殊处理,所以当终端连接中断时(远程终端应用程序被关闭),慢悠悠的编译进程也就这么被终止了。
永不消逝的进程 v1:
下面让我们通过一个实际例子来看一看一个被 nohup 处理过的进程在其所属的会话的控制进程收到 SIGHUP 信号时会发生些什么:
清单 4 实例:一个 nohup 处理过的进程
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
#首先远程 SSH 登陆一台 Linux 服务器
$ ssh zhang@9.115.241.18
#然后打开一个后台进程 (27871) 直接进入休眠
$ nohup sleep 1000 &
[1] 10590
#利用 ps j 命令来查看一下 27871 进程的作业(job)相关信息
$ ps j 10590
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
10417 10590 10590 10417 pts/20 10655 S 1000 0:00 sleep 1000
#一切正常,现在断开连接,关闭会话
$ exit
#最后再在远程运行 ps -j 命令来检查 10590 进程当前的状态
$ ssh zhang@9.115.241.18 ‘ps -j’
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
1 10590 10590 10417 ? -1 S 1000 0:00 sleep 1000
|
比较一下 exit 前后的 ps 输出,可以发现:
- 由于原有父进程 10417 已死,10590 变成了孤儿进程(orphan);
- 由于 pts/20 随着会话 10417 被关闭了,TTY 和 TPGID 被置为了?和-1;
- 而原有的 PGID 和 SID 保持不变,只不过 process group leader 和 session leader 分别变成了 10590;
因此,我们得出了结论:一个忽略了 SIGHUP 信号的进程,在它所属的会话的控制进程被终结之后依旧可以继续运行;但此时由于原有控制终端已经不再存在了,它便不再有终端输入或输出的能力;此外,原有的会话依旧存在,只不过会话先导(session leader,由于此时的会话中已没有任何终端,因此不能称之为控制进程了)变为该进程。
总而言之,看起来 SIGHUP 基本可以满足笔者的需求了,下文的清单 5 是笔者对清单 1 中例程略作修改之后的结果,这一次,即使 shell 进程被关闭,child process 仍然可以继续在后台欢快的运行,称得上拥有"不死之身"了。有兴趣的读者可以在自己的环境里尝试一下。
清单 5 永不消逝的进程 v1
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
import signal
import time
from multiprocessing import Process
from os import getpid
def child_process():
# child process
# 忽略 child process 的 SIGHUP 信号
signal.signal(signal.SIGHUP, signal.SIG_IGN)
print("child process's pid: %d" % getpid())
while (1):
print("child's still alive.")
time.sleep(1)
def main():
p = Process(target=child_process)
"""
这里就不能再设置 daemon 属性为 True 了,
因为如果 daemon 属性为 True,则 Process 进程结束时会自动 terminate 所有的子进程
这样就没 SIGHUP 什么事了
"""
p.start()
# parent process
print("Parent process ends here.")
print("Will child process live forever?")
if __name__ == '__main__':
main()
|
看着 ps 输出里的 client process 在那里闷声发大财,是不是有点小激动?好,现在到了泼冷水的时候了,下面咱们来探讨一下用屏蔽 SIGHUP 实现出的"不死"进程都有些什么痛脚。
nohup 的局限性
咱们先来说结论,用屏蔽 SIGHUP 的方式来实现守护进程,平时个人用用偷着乐还行;真要做成通用的解决方案,那还是有一定差距的。
最容易想到的问题来自于易用性:显而易见,控制进程被杀之后带来的最直接的软肋就是控制终端就此失效,这给想要获取程序的运行状态的用户带来了一个难题。以前文的'nohup make &'为例,nohup 会很体贴的默认将应用程序的 stdout 或 stderr 转到文件 nohup.out 之中,但如若这个文件被删,那就欲哭无泪了。因此为守护进程提供一个稳定的执行结果输出方案是非常必要的;
获取了输出,那下一步要考虑的就是如何对守护进程输入了:一般来说,配置文件是这类问题的入门机配置。但是,如何告诉一个正在运行的进程去重新载入用户刚刚修改过的配置呢?如果你不打算额外实现点什么,那么最简便的方法就是利用操作系统已经实现好了的机制:信号。
那么问题又来了,使用什么信号量告诉程序重载配置文件比较好呢?很遗憾,解决这个问题的常规方式还是 SIGHUP,理由也比较充分:POSIX 中信号量的确是定义了不少,但却各司其职;且守护进程本就没有控制终端了,那不用 SIGHUP 用谁?
于是我们又开始要面对一个小小的悖论了:屏蔽 SIGHUP 真的好吗?
当然,上面说的两点之外,我们还需要面对一箩筐的问题:比如守护进程的工作目录无法被 umount;再比如绝对不可以允许守护进程再偷偷的拥有一个控制终端;再比如如何清理那些遗留在系统边边角角的守护进程……
成功?我们才刚上路呢。
守护着 Service 的进程
在上一章中,笔者详细向读者们介绍了进程组和会话的前世今生、工作原理、以及 nohup 是如何基于这些工作原理来创建出守护进程的;诚然,nohup 的方法并不完美,绝非铁板一块,所以最后,笔者又狠狠的"黑"了一把 nohup。当然这并不代表笔者认为 nohup 不好,恰恰相反,在很多场景,屏蔽 SIGHUP 是非常便捷的实现守护进程的手段;但这个手段并不适合所有的场景,比如:服务(service)。
在 Linux 中,服务是最需要的守护进程的,大部分的服务的生命周期都伴随着 init 进程的开启直到系统重启始终。显而易见,利用 nohup 的手法来实现这样的进程是不靠谱的,毕竟服务进程连控制终端都没有,所谓的屏蔽 SIGHUP 也就无从谈起了。
那么用于服务的守护进程应该如何实现呢?
其实我们什么都不用做,因为 glibc 为已经把实现守护进程所需的绝大部分工作都封装到 daemon 函数中了。
daemon()
daemon()的函数原型如下:
int daemon (int nochdir, int noclose)
这个函数的使用非常简单,甚至比 fork()还要方便:只要调用一次,当前进程自动变成守护进程。
作为一个喜欢打破沙锅问到底的工程师,我想读者们应该和我一样很好奇 daemon 到底做了些什么?幸而函数的实现并不长,我们很容易就可以一窥究竟(中文注释为笔者所加):
清单 6 daemon.c
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
int daemon (int nochdir, int noclose)
{
int fd;
/* 步骤 1: fork 出一个新的子进程,用以开启新的会话 */
switch (__fork()) {
case -1:
return (-1);
case 0:
break;
default:
_exit(0);
}
/* 步骤 2: 开启一个新的会话 */
if (__setsid() == -1)
return (-1);
if (!nochdir)
/* 步骤 3: 把进程当前的执行路径换到根目录 */
(void)__chdir("/");
if (!noclose) {
/* 步骤 4: 将当前进程的标准输入、输出和错误都重定向到/dev/null */
struct stat64 st;
if ((fd = open_not_cancel(_PATH_DEVNULL, O_RDWR, 0)) != -1
&& (__builtin_expect (__fxstat64 (_STAT_VER, fd, &st), 0)
== 0)) {
/* …… */
(void)__dup2(fd, STDIN_FILENO);
(void)__dup2(fd, STDOUT_FILENO);
(void)__dup2(fd, STDERR_FILENO);
/* …… */
}
}
return (0);
}
|
在解读上述代码之前,有一些比较容易让人困惑的坑是要注意一下的:
- open_not_cancel 是一个宏定义,根据不同的操作系统选择指向 openat 或 open 系统调用。当然,在 daemon 中这两个系统调用没有差别;
- __builtin_expect 是 gcc 中独有的一种机制,主要用于告知编译器其中所包含的代码最有可能的返回值,以协助编译器据此进行优化。在 Linux 内核中这种机制被大规模使用;
从代码中我们可以看到 daemon 的实现主要分为四个步骤,简单概括起来就是:一、建立一个新进程(fork)并为之开启一个新的会话(setsid);二、其他。
从笔者的表述中大家应该可以意识到建立一个新的会话的重要性了,由清单 6 可以猜到 setsid 便是用于建立新会话的系统调用。在执行完 setsid 之后,内核会做以下几件事:
- 建立一个新的会话,当前进程会成为新会话的会话先导(session leader);
- 当前进程由原有进程组撤出,创建出一个新的进程组,当前进程成为新进程组的进程组先导;
但是这里的实现还是有些略微的让人感到匪夷所思,为什么一定要:1、先 fork 出一个新的进程;2、再杀死父进程;3、最后再调用 setsid 呢?
这主要是由于 setsid 的正常调用有一个前提条件:它要求调用它的进程不可以是一个进程组先导(progress group leader),否则将返回错误;因此,通常在执行 setsid 之前都会先调用一次 fork 并杀死父进程,因为 fork 出的子进程必然和父进程在同一个进程组之内,且进程组先导必然不为子进程(要么是父进程要么是其他进程),因此逻辑上如此创建出的新进程之上运行 setsid 一定能够成功。
另一个值得注意的是当前进程在运行了 setsid()之后不在会关联任何的控制终端,因为由 setsid()创建出的新会话默认是没有控制终端的——这符合我们对于服务进程的预期,但是也带来了一个争议:虽然由 daemon()建立的新会话没有控制终端,但它也没有办法阻止开发者在之后的实现中另开一个。对于一个通用的 API 来说,这的确不是个好事。
要解决这一问题并非没有可能,两部 Linux/Unix 开发方面的经典砖头:TLPI(The Linux Programming Interface,参考文献 4)和 APUE(Advanced Programming in Unix Environment,参考文献 5)都提到了 System-V 下的解决方案:在 setsid()之后再 fork 出一个新的子进程,并杀死原有父进程——这么做之后,根据 System V 的规则,用户便无法再在这样的进程上下文中开启控制终端了。
然而很遗憾,源自 BSD 的 daemon()并没有将这一设计加入进来,因为同样的机制在 BSD 下无效。因此在 BSD 系的 Unix 下(如 FreeBSD,NetBSD 等),我们就只有祈祷开发者会自觉的在开启终端时加上 O_NOCTTY 了;不过由于 Linux 是参照 System-V 的接口定义设计其行为的,所以我们还是可以在调用了 daemon()之后再按照 System-V 的方案做一遍以防不测。
setsid()之外
讨论完了 setsid()的话题,现在我们再来讨论一下 daemon()实现中相对不那么重要的"其他"步骤:
- 切换工作进程:daemon 函数会可选的将进程的工作目录切换到根目录。这一步被设为可选,因为本质上它并不会影响到守护进程的运行。但问题是工作目录所属的文件系统会无法被 umount,尤其是对于那些由 shell 启动的守护进程:回想一下在 windows 下莫名无法被移除的 U 盘给人带来的困扰,这的确是够令人厌烦的。当然,其实我们也不一定非要将守护进程的工作目录切换到根目录,只要切换到那些在系统运行的过程中绝对不会被 umount 的目录,例如/tmp,也是可以接受的。尤其是对于一些在运行的过程中需要利用文件来存储运行时信息的守护进程,这时候将工作目录迁移至记载着运行时信息的目录,例如/var/XXX,会是一个非常好的主意。
- 将 stdin/stdout/stderr 重定向到/dev/null:诚然,守护进程是不可以拥有控制终端的,所以按理说标准输入输出和错误应该是没有任何作用才是。但是作为一个通用的 API,如果选择将这些文件描述符直接关闭也不合时宜,因为如果这样在进程后续的上下文中如果有任何打开文件的操作,那么 0、1、2 这些约定俗成的描述符就会在不经意间误作它用,这对程序安全是一个隐患。所以一个比较理性的做法是将这些描述符重定向到/dev/null 上,这样无论后续的上下文如何操作文件都不会有任何负面影响,且任何针对标准输入、输出和错误的 IO 操作都不会导致系统报错。
永不消逝的进程 v2:
总而言之,有了上一章的理论铺垫,笔者将清单 5 中的例程进化了一次,如清单 7 所示:
清单 7 永不消逝的进程 v2
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
#! /usr/bin/python
import time
import sys
import os
import logging
def child_process():
logging.info("child process's pid: %d" % os.getpid())
while (1):
logging.info("child's still alive.")
time.sleep(1)
def fork_and_exit_parent_proc():
# 因为 multiprocessing.Process 的既定设计是只在子进程中运行 target 参数所指向的函数对象
# 因此这里我们必须回归传统的 fork
pid = os.fork()
if pid > 0:
os._exit(0)
def become_daemon(target):
# 1. 第一次 fork
fork_and_exit_parent_proc()
# 2. 创建新会话
os.setsid()
# 3. 第二次 fork
fork_and_exit_parent_proc()
# 4. 将工作目录切换至 '/'
os.chdir('/')
# 5. 重定向标准输入、输出、错误至/dev/null
fd = os.open(os.devnull, os.O_RDWR)
os.dup2(fd, sys.stdin.fileno())
os.dup2(fd, sys.stdout.fileno())
os.dup2(fd, sys.stderr.fileno())
# 6. 因为标准输出不可用,这里笔者又额外定义了一个 log 文件以接收守护进程的输出
logging.basicConfig(filename='/var/log/mylog.log', level=logging.INFO)
target()
def main():
become_daemon(target=child_process)
if __name__ == '__main__':
main()
|
在清单 7 中,笔者并未直接调用 daemon(),这主要是因为 python 的标准库中并未包含对 daemon()的直接封装(其实 python 中也提供了其他方案,笔者下文中会有提及)。此外,由于上述实现中有很多调用都需要系统管理员权限,因此必须要以 root 或者 sudoer 的身份才可以执行。
读到这里让我们再回到上一章末尾处的思考:服务级的守护进程纵有千般好,毕竟需要用到系统管理员级的权限;而屏蔽 SIGHUP 纵有千般不是,一个的普通用户权限即可驱动——故而技术无贵贱,不同技术适用于不同场合而已。
最后,除去上述步骤之外,还有一些上述代码中并未实现,但对于守护进程大有裨益的工作,笔者也罗列如下:
- 利用 umask 限制进程新建文件的权限位,以确保运行时创建的文件不会被外界非法修改,从而改变守护进程的运行时行为。例如 openssh 的服务进程就禁止了新建文件的用户组和其他用户的写行为;
- 关闭所有非必需的自父进程继承而来的文件描述符。诚然,这一部分工作不一定必须由 daemon 之类的 API 直接实现,但考虑到守护进程长期运行的特性,又是必须完成的;
- 实现一个外界同守护进程交互的方案。显而易见,守护进程一般游离于终端之外,除开 ps 或查询/proc 之类的方法之外难觅其踪。自然用户会需要一个接口来对其进行控制。顺便一提,纵然 Linux 下的进程间交互手段五花八门,不过由于许多约定俗成的习惯,信号量始终是最为行之有效的控制守护进程方案之一。例如上文中提到过的 SIGHUP 就通常用于通知守护进程重新载入配置文件(准确的说,是用于通知守护进程重新初始化),绝大部分传统的守护进程实现都会支持这一功能;
- 实现一个守护进程输出自身运行时状态的方案,理由同上。很多笔者可能会说这部分工作可以利用系统的 log 服务来完成。其实这里还有一个约定俗成的做法,就是大多数守护进程都会在/var/run 下创建一个 xxx.pid 文件以方便利用脚本来追踪进程的运行状态。例如,如果想要查询当前系统的 rsyslogd 进程的 pid,直接在/var/run 下查询 rsyslogd.pid 文件的内容即可;
总而言之守护进程的实现要考虑到非常多的因素,毕竟你实现的是一个长时间在操作系统的后台蹦跶的程序,哪怕有一点点小的要素没有考虑到都会导致系统运行效率的降低、死机甚至被居心叵测的黑客实施攻击。虽然 daemon()这样的通用 API 一定程度上减轻了我们的工作量,但是前面还是会有很多额外的坑在等待着我们,所谓路漫漫其修远兮……
回到 python
现在让我们再回到本文最开始的地方:笔者最初的目的其实只是实现一个通用且稳定的守护进程,但是现在,看看清单 5 中简陋的的 v1 版和清单 7 中偷工减料的 v2 版,不禁仰声长叹:难道就没有一个能让人乐得逍遥且又面面俱到的 v3 版么?
Python 的标准库中并没有封装 glibc 中的 daemon()函数,这个笔者在前文有提到过,但这不代表社区中没人考虑过这个问题:PEP-3143就详细探讨了一个守护进程库的解决方案。
PEP-3143 的设计非常简明扼要:一个 DaemonContext 类就可以基本可以提供开发者们需要的一切,其主要接口和属性定义如下表所示:
表 1 DaemonContext 类的定义

一切看起来都挺美好的,唯一的缺陷是:这个 PEP 被 defer 了,直到今天也没有进入标准库。不过不要紧,因为这个 PEP 还有一个参考实现 python-daemon,在pip中很容易找到源码。
终章:永不消逝的进程 v3
凭借 python-daemon,我们的永不消逝的进程终又可以再进化一层,笔者将修改后的源码列于清单 8 之中,作为本章的结尾以飨读者:
清单 8 永不消逝的进程 v3
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
#! /usr/bin/python
import time
import os
import logging
import daemon
def child_process():
logging.info("child process's pid: %d" % os.getpid())
while (1):
logging.info("child's still alive.")
time.sleep(1)
def main():
# DaemonContext 实现了__enter__() 和__exit__(),因此我们可以一句话搞定整个 daemon context
with daemon.DaemonContext():
# daemon 目前不支持 log,所以这部分工作只能我们手动初始化
logging.basicConfig(filename='/var/log/mylog.log', level=logging.INFO)
child_process()
if __name__ == '__main__':
main()
|
结束语
后台守护进程是 Linux/Unix 系统中非常重要的"地下工作者"。本文从 Linux/Unix 的进程组和会话的机制入手,详细的介绍了基于这些机制之上的两种截然不同的实现守护进程的手法。在深入解读这些奇淫巧技的同时,笔者也更希望读完本文的朋友们能够触类旁通,对 Linux/Unix 系统的进程间关系能有更深一层的认识。
- 安卓客户端下载
- 微信扫一扫
-

- 微信公众号
- 微信公众号扫一扫
-