- A+
【摘要】 本文简单介绍下集群间的HBASE数据备份(导入导出),即主集群往备集群上备份(同步)数据的主要方式 当前HBASE上可以使用的数据备份主要有以下几种u Snapshotsu Replicationu Exportu CopyTableu HTable APIu Offline backup of HDFS data分别从操作对集群的性能影响、数据空间消耗、业务中断影响、增量备份、...
本文简单介绍下集群间的HBASE数据备份(导入导出),即主集群往备集群上备份(同步)数据的主要方式
HBASE作为当前火热的大数据存储服务,自身提供了多种备份方式,来满足不同的条件和需求下对数据的同步,当前HBASE上可以使用的数据备份主要有以下几种
- Snapshots
- Replication
- Export
- CopyTable
- HTable API
- Offline backup of HDFS data
分别从操作对集群的性能影响、数据空间消耗、业务中断影响、增量备份、易用性、可恢复性几个维度进行了如下的对比:
| Performance Impact | Data Footprint | Downtime | Incremental Backups | Ease of Implementation | Mean Time To Recovery (MTTR) | |
| Snapshots | Minimal | Tiny | Brief (Only on Restore) | No | Easy | Seconds |
| Replication | Minimal | Large | None | Intrinsic | Medium | Seconds |
| Export | High | Large | None | Yes | Easy | High |
| CopyTable | High | Large | None | Yes | Easy | High |
| API | Medium | Large | None | Yes | Difficult | Up to you |
| Manual | N/A | Large | Long | No | Medium | High |
以上备份方法除了Replication都可以在当前集群备份数据,由于本集群数据备份和本远端备份的操作流程相似,本文以下内容就只讨论集群间的数据备份
离线数据备份
离线数据备份,顾名思义它需要中断当前主集群和备集群的业务
主要执行步骤为:
#主集群
1)对当前集群中表数据执行flush操作,将当前内存中的数据持久化到hdfs中
flush ‘tableName’ 2)停止HBASE 3)使用distcp命令拷贝当前集群hdfs上的数据到备集群上hadoop distcp -i /hbase/data hdfs://1.1.1.2:25000/hbase hadoop distcp –update –append –delete /hbase/ hdfs:// 1.1.1.2:25000/hbase/
---1.1.1.2:25000为备集群hdfs主nn节点的ip/端口
---第二条增量拷贝主要是为了拷贝除了data目录以外的文件,例如archive里面的数据可能当前还有被数据目录所引用
#备集群
1)重启hbase
2)执行hbase hbck检查是否表中所有region都已经上线
注意:当用户使用了hbase协处理器,自定义jar包放在主集群的regionserver/hmaster上时,在备集群重启hbase之前,需要把这些自定义jar包也拷贝过来
此种方式数据备份的优点:
1) 简单暴力,可以一下子把主集群上所有数据(包含元数据)整个复制到备集群
2) 由于是通过distcp直接拷贝的,所以数据备份的效率相对较高
3) 实际操作时可以根据具体的需求灵活拷贝,可以只拷贝其中一个表的数据,也可以拷贝region中的其中一个hfile等。
缺点和限制:
1) 此操作对备集群上的hdfs的数据目录会有破坏性(整个覆盖了)
2) 如果主备集群间的hbase版本不同,hdfs目录直接拷贝可能会出现问题,例如MRS上的hbase1.3版本新增了系统表index,如果使用老版本的hdfs目录直接覆盖,会找不到该数据表。所以此种方案在执行前需要慎重考虑
3) 操作对hbase的能力有一定的要求,如出现异常情况需要根据实际情况执行恢复
Export和import导入导出数据
Export/Import主要是启动MR任务对 数据的表进行scan扫描,往远端hdfs写入SequenceFile,之后Import再把SequenceFile读出来写入hbase(put)
可以参考以下操作:
#主集群
1)执行表的Export操作
hbase org.apache.hadoop.hbase.mapreduce.Export member hdfs://10.120.169.46:25000/user/table/member
---member为表名
---10.120.169.46为远端hdfs的主nn节点ip
#备集群
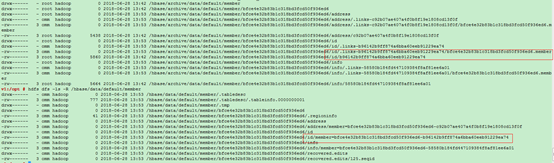
1)主机群执行完之后可以在备集群上查看生成的目录数据如下:
![]()
2)在备集群上新建与主机群相同结构的表
create 'member_import','id','address','info'
3)执行Import导入操作
hbase org.apache.hadoop.hbase.mapreduce.Import member_import -Dimport.bulk.output=/tmp/member /user/table/member
--- member_import为备集群上与主集群相同表结构的表
--- Dimport.bulk.output 执行完数据的输出目录
---/user/table/member 为从主集群上导出的数据目录
4)执行load操作
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /tmp/member member
----/tmp/member 步骤3中hfile数据的输出路径
----member 备集群上要导入数据的表名
此种方式的优点:
1)在线拷贝不中断业务,由于是scan->put的方式写入新表,所以比CopyTable更加灵活,可灵活配置需要获取的数据,数据可增量写入
限制和约束:
1)由于Export是通过MR任务往远端hdfs写入SequenceFile,之后Import再把SequenceFile读出来写入hbase,实际效率不高,且需要跑两次MR任务
使用snapshot备份表数据
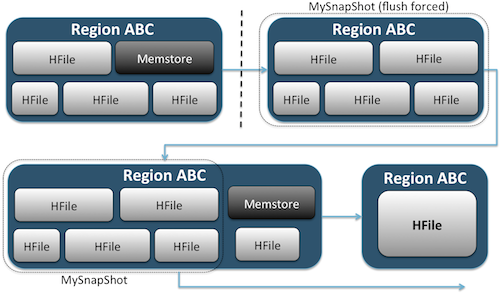
对表执行snapshot操作生成快照,既可以作为原表的备份,当原表出现问题的时候可以回滚恢复,也可以作为跨集群的数据备份工具。
执行快照会在当前hbase在hdfs上的根目录(默认为/hbase),生成” .hbase-snapshot”目录,里面有每个快照的详细信息。
当执行ExportSnapshot导出快照时,会在本地提交MR任务,将快照信息以及表的hfile分别拷贝到备集群的/hbase/.hbase-snapshot和/hbase/archive
操作可以参考以下过程:
#主集群
1)对表member创建快照member_snapshot
restore_snapshot 'member','member_snapshot'
2)将快照拷贝到备集群上
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot member_snapshot -copy-to hdfs://10.120.169.46:25000/hbase -mappers 3
注意远端的数据目录必须为HBASE根目录(/hbase)
---- mappers 表示MR任务需要起的map个数
#备集群
1)使用restore命令后会在备集群自动新建表,以及与archive里的hfile建立link
restore_snapshot 'member_snapshot'

PS:如果只是备份表数据的话,建议使用此种方式备份, SnapshotExport会在本地起MR任务,将snapshot和hfile拷贝到备集群,之后可以在备集群直接load,效率比其他方式高很多。
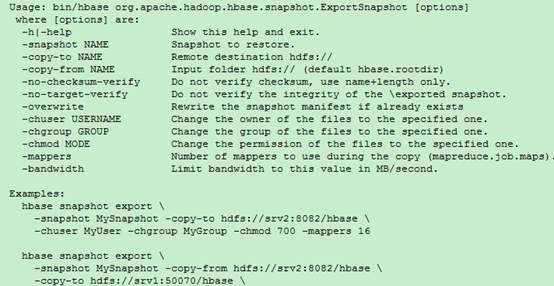
snapshot命令介绍:
此种方式的优点:
1)单表备份效率高,在线数据本地/远程备份,不中断主机群和备集群业务,可以灵活配置map的个数和限制流量,MR的执行节点可不在主备集群(不占资源)
限制和约束:
2)只能单表操作,备份的表名在snapshot中已经指定无法更改,且无法增量备份,跑MR需要占用本地集群资源
官网链接:http://hbase.apache.org/1.2/book.html#ops.snapshots
CopyTable拷贝表数据
#主集群
1)执行CopyTable的命令(这之前备集群必须手动新建和主集群结构相同的表member_copy)
hbase org.apache.hadoop.hbase.mapreduce.CopyTable [--starttime=1265875194289] [--endtime=1265878794289] --new.name=member_copy --peer.adr=server1,server2,server3:2181:/hbase [--families=myOldCf:myNewCf,cf2,cf3] TestTable
---- starttime/ endtime需要拷贝数据的timestamp
---- new.name目的表的表名,缺省为和原来表名相同
---- peer.adr 目标集群zk节点的信息,格式为quorumer:port:/hbase
---- families 需要拷贝的表的family列
注意:如果是拷贝数据到远端集群,此种方式导入数据会在主机群上起MR任务,读取原始表的全量/部分数据之后采用put的方式写入远端集群,所以如果表的数据量很大(远程拷贝不支持bulkload),则效率会比较低
此种方式的优点:
1)操作简单,在线拷贝不中断业务,可以指定备份数据的startrow/endrow/timestamp
限制和约束:
2)只能单表操作,远程拷贝数据量大时效率较低,MR需要占用本地资源,MR的map个数以表region的个数划分
CopyTable命令介绍
官网参考链接:http://hbase.apache.org/1.2/book.html#copy.table
Replication容灾备份
Replication容灾备份是在hbase上建立主备集群的容灾关系,当数据写入主集群,主集群通过WAL来主动push数据到备集群上,从而达到主备集群的实时同步。
此种方式的优点:
1) 使用replication有别与其他几种数据备份导入方式,当配置了集群间的主备关系后,数据可以实时同步(无需人为操作)
2) 相对而言,“备份”的动作占用集群的资源较少,对集群的性能影响小
3) 数据同步可靠性较高,如果备集群停止一段时间后再恢复,这中间主机群的数据依然会同步到备集群
限制和约束:
1) 如果客户端写入的数据设置不写WAL,则数据无法备份到备集群
2) 由于占用的资源少,后台是通过异步的方式同步数据,实际数据没有实时同步
3) 对于开启表replication同步之前,主集群就已经存在的数据无法同步,需要借助其他方式导入的备集群
4) bulkload方式写入到主集群的数据无法同步(MRS上的hbase对replication做了增强,支持bulkload on replication)
官网介绍链接:http://hbase.apache.org/1.2/book.html#_cluster_replication
综上,每种备份方式都有各自的优点和限制,用户可以结合自身的业务场景来选择具体适合使用哪种数据备份方式。API的方式主要也是在代码中对原始hbase表的数据导入导出(也可以使用像snapshot这些API接口),此次不做赘述,如果有这块需要,会单独做详细介绍
参考链接:http://blog.cloudera.com/blog/2013/11/approaches-to-backup-and-disaster-recovery-in-hbase/
- 安卓客户端下载
- 微信扫一扫
-

- 微信公众号
- 微信公众号扫一扫
-