- A+
Elasticsearch (ES)是一个基于 Lucene 的开源搜索引擎,它不但稳定、可靠、快速,而且也具有良好的水平扩展能力,是专门为分布式环境设计的。

特性
- 安装方便:没有其他依赖,下载后安装非常方便;只用修改几个参数就可以搭建起来一个集群
- JSON:输入/输出格式为 JSON,意味着不需要定义 Schema,快捷方便
- RESTful:基本所有操作(索引、查询、甚至是配置)都可以通过 HTTP 接口进行
- 分布式:节点对外表现对等(每个节点都可以用来做入口);加入节点自动均衡
- 多租户:可根据不同的用途分索引;可以同时操作多个索引
集群
其中一个节点就是一个 ES 进程,多个节点组成一个集群。一般每个节点都运行在不同的操作系统上,配置好集群相关参数后 ES 会自动组成集群(节点发现方式也可以配置)。集群内部通过 ES 的选主算法选出主节点,而集群外部则是可以通过任何节点进行操作,无主从节点之分(对外表现对等/去中心化,有利于客户端编程,例如故障重连)。
分片
ES 是一个分布式系统,我们一开始就应该以集群的方式来使用它。它保存索引时会选择适合的“主分片”(Primary Shard),把索引保存到其中(我们可以把分片理解为一块物理存储区域)。分片的分法是固定的,而且是安装时候就必须要决定好的(默认是 5),后面就不能改变了。
既然有主分片,那肯定是有“从”分片的,在 ES 里称之为“副本分片”(Replica Shard)。副本分片主要有两个作用:
- 高可用:某分片节点挂了的话可走其他副本分片节点,节点恢复后上面的分片数据可通过其他节点恢复
- 负载均衡:ES 会自动根据负载情况控制搜索路由,副本分片可以将负载均摊
索引

RESTful
这个特性非常方便,最关键的是 ES 的 HTTP 接口不只是可以进行业务操作(索引/搜索),还可以进行配置,甚至是关闭 ES 集群。下面我们介绍几个很常用的接口:
- /_cat/nodes?v:查集群状态
- /_cat/shards?v:查看分片状态
- /${index}/${type}/_search?pretty:搜索
v 是 verbose 的意思,这样可以更可读(有表头,有对齐),_cat 是监测相关的 APIs,/_cat?help 来获取所有接口。${index} 和 ${type} 分别是具体的某一索引某一类型,是分层次的。我们也可以直接在所有索引所有类型上进行搜索:/_search。
日志处理
前面介绍了那么多Elasticsearch简介和特性,大多源自官方介绍和百度,其实写这篇文章的目的就是如何基于Elasticsearch构建网站日志处理系统,通过数据同步工具等一些列开源组件来快速构建一个日志处理系统,后面附项目Demo雏形,并不完善,初步成型中。
开发环境
JDK1.7、Maven、Eclipse、SpringBoot1.5.9、elasticsearch2.4.6、Dubbox2.8.4、zookeeper3.4.6、Vue、Iview
版本介绍
spring-boot-starter-parent-1.5.9.RELEASE、spring-data-elasticsearch-2.1.9.RELEAS、elasticsearch-2.4.6(5.0+以上需要依赖JDK8)
截止2018年1月22日,ElasticSearch目前最新的已到6.1.2,但是spring-boot的更新速度远远跟不上ElasticSearch更新的速度,目前spring-boot支持的最新版本是elasticsearch-2.4.6。
服务说明
使用本地ElasticSearch服务(application-dev.properties)
spring.data.elasticsearch.cluster-name=elasticsearch#默认就是本机,如果要使用远程服务器,或者局域网服务器,那就需要在这里配置ip:prot;可以配置多个,以逗号分隔,相当于集群。#Java客户端:通过9300端口与集群进行交互#其他所有程序语言:都可以使用RESTful API,通过9200端口的与Elasticsearch进行通信。#spring.data.elasticsearch.cluster-nodes=192.168.1.180:9300
使用远程ElasticSearch服务(application-dev.properties)
- 需要自行安装ElasticSearch,注意ElasticSearch版本尽量要与JAR包一致。
- 下载地址:https://www.elastic.co/downloads/past-releases/elasticsearch-2-4-6
- 安装说明:http://www.52itstyle.com/thread-20114-1-1.html
- 新版本不建议使用root用户启动,需要自建ElasticSearch用户,也可以使用以下命令启动 elasticsearch -Des.insecure.allow.root=true -d 或者在elasticsearch中加入ES_JAVA_OPTS=”-Des.insecure.allow.root=true”。
项目结构
├─src │ ├─main │ │ ├─java │ │ │ └─com │ │ │ └─itstyle │ │ │ └─es │ │ │ │ Application.java │ │ │ │ │ │ │ ├─common │ │ │ │ ├─constant │ │ │ │ │ PageConstant.java │ │ │ │ │ │ │ │ │ └─interceptor │ │ │ │ MyAdapter.java │ │ │ │ │ │ │ └─log │ │ │ ├─controller │ │ │ │ LogController.java │ │ │ │ │ │ │ ├─entity │ │ │ │ Pages.java │ │ │ │ SysLogs.java │ │ │ │ │ │ │ ├─repository │ │ │ │ ElasticLogRepository.java │ │ │ │ │ │ │ └─service │ │ │ │ LogService.java │ │ │ │ │ │ │ └─impl │ │ │ LogServiceImpl.java │ │ │ │ │ ├─resources │ │ │ │ application-dev.properties │ │ │ │ application-prod.properties │ │ │ │ application-test.properties │ │ │ │ application.yml │ │ │ │ spring-context-dubbo.xml │ │ │ │ │ │ │ ├─static │ │ │ │ ├─iview │ │ │ │ │ │ iview.css │ │ │ │ │ │ iview.min.js │ │ │ │ │ │ │ │ │ │ │ └─fonts │ │ │ │ │ ionicons.eot │ │ │ │ │ ionicons.svg │ │ │ │ │ ionicons.ttf │ │ │ │ │ ionicons.woff │ │ │ │ │ │ │ │ │ ├─jquery │ │ │ │ │ jquery-3.2.1.min.js │ │ │ │ │ │ │ │ │ └─vue │ │ │ │ vue.min.js │ │ │ │ │ │ │ └─templates │ │ │ └─log │ │ │ index.html │ │ │ │ │ └─webapp │ │ │ index.jsp │ │ │ │ │ └─WEB-INF │ │ web.xml │ │ │ └─test │ └─java │ └─com │ └─itstyle │ └─es │ └─test │ Logs.java │
项目演示
演示网址:http://es.52itstyle.com
项目截图
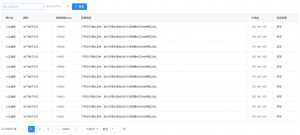
分页查询
使用ElasticsearchTemplate模板插入了20万条数据,本地向外网服务器(1核1G),用时60s+,一分钟左右的时间。虽然索引库容量有增加,但是等了大约 10分钟左右的时间才能搜索出来。
分页查询到10000+的时候系统报错,Result window is too large,修改config下的elasticsearch.yml 追加以下代码即可:
# 自行定义数量index.max_result_window : '10000000'
参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules.html
Java API
Elasticsearch为Java用户提供了两种内置客户端:
- 节点客户端(node client):
节点客户端,顾名思义,其本身也是Elasticsearch集群的一个组成部分。以无数据节点(none data node)身份加入集群,换言之,它自己不存储任何数据,但是它知道数据在集群中的具体位置,并且能够直接转发请求到对应的节点上。 - 传输客户端(Transport client):
这个更轻量的传输客户端能够发送请求到远程集群。它自己不加入集群,只是简单转发请求给集群中的节点。两个Java客户端都通过9300端口与集群交互,使用Elasticsearch传输协议(Elasticsearch Transport Protocol)。集群中的节点之间也通过9300端口进行通信。如果此端口未开放,你的节点将不能组成集群。
安装Elasticsearch-Head
elasticsearch-head是一个界面化的集群操作和管理工具,可以对集群进行傻瓜式操作。你可以通过插件把它集成到es(首选方式),也可以安装成一个独立webapp。
es-head主要有三个方面的操作:
- 显示集群的拓扑,并且能够执行索引和节点级别操作
- 搜索接口能够查询集群中原始json或表格格式的检索数据
- 能够快速访问并显示集群的状态
插件安装方式、参考:https://github.com/mobz/elasticsearch-head
- for Elasticsearch 5.x: site plugins are not supported. Run as a standalone server
- for Elasticsearch 2.x: sudo elasticsearch/bin/plugin install mobz/elasticsearch-head
- for Elasticsearch 1.x: sudo elasticsearch/bin/plugin -install mobz/elasticsearch-head/1.x
- for Elasticsearch 0.x: sudo elasticsearch/bin/plugin -install mobz/elasticsearch-head/0.9
安装成功以后会在plugins目录下出现一个head目录,表明安装已经成功。
浏览截图:
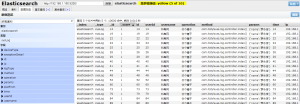
x-pack监控
Elasticsearch、Logstash 随着 Kibana 的命名升级直接从2.4跳跃到了5.0,5.x版本的 ELK 在版本对应上要求相对较高,不再支持5.x和2.x的混搭,同时 Elastic 做了一个 package ,对原本的 marvel、watch、alert 做了一个封装,形成了 x-pack 。
安装:https://www.elastic.co/guide/en/elasticsearch/reference/6.1/installing-xpack-es.html
用户管理
x-pack安装之后有一个超级用户elastic ,其默认的密码是changeme,拥有对所有索引和数据的控制权,可以使用该用户创建和修改其他用户,当然这里可以通过kibana的web界面进行用户和用户组的管理。
修改elastic用户的密码:
curl -XPUT -u elastic 'localhost:9200/_xpack/security/user/elastic/_password' -d '{"password" : "123456"}'
IK Analysis for Elasticsearch
下载安装:
- 方式一 - download pre-build package from here:https://github.com/medcl/elasticsearch-analysis-ik/releases unzip plugin to folder your-es-root/plugins/
- 方式一二 - use elasticsearch-plugin to install ( version > v5.5.1 ): ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.0.0/elasticsearch-analysis-ik-6.0.0.zip
由于Elasticsearch版本是2.4.6,这里选择IK版本为1.10.6
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v1.10.6/elasticsearch-analysis-ik-1.10.6.zip
下载解压以后在 Elasticsearch 的config下的elasticsearch.yml文件中,添加如下代码(2.0以上可以不设置)。
index:analysis:analyzer:ik:alias: [ik_analyzer]type: org.elasticsearch.index.analysis.IkAnalyzerProviderik_max_word:type: ikuse_smart: falseik_smart:type: ikuse_smart: true
或者
index.analysis.analyzer.ik.type : “ik”
安装前:
http://192.168.1.180:9200/_analyze?analyzer=standard&pretty=true&text=我爱你中国{"tokens" : [ {"token" : "我","start_offset" : 0,"end_offset" : 1,"type" : "<IDEOGRAPHIC>","position" : 0}, {"token" : "爱","start_offset" : 1,"end_offset" : 2,"type" : "<IDEOGRAPHIC>","position" : 1}, {"token" : "你","start_offset" : 2,"end_offset" : 3,"type" : "<IDEOGRAPHIC>","position" : 2}, {"token" : "中","start_offset" : 3,"end_offset" : 4,"type" : "<IDEOGRAPHIC>","position" : 3}, {"token" : "国","start_offset" : 4,"end_offset" : 5,"type" : "<IDEOGRAPHIC>","position" : 4} ]}
安装后:
http://121.42.155.213:9200/_analyze?analyzer=ik&pretty=true&text=我爱你中国{"tokens" : [ {"token" : "我爱你","start_offset" : 0,"end_offset" : 3,"type" : "CN_WORD","position" : 0}, {"token" : "爱你","start_offset" : 1,"end_offset" : 3,"type" : "CN_WORD","position" : 1}, {"token" : "中国","start_offset" : 3,"end_offset" : 5,"type" : "CN_WORD","position" : 2} ]}
数据同步
使用第三方工具类库elasticsearch-jdbc实现MySql到elasticsearch的同步。

运行环境:
centos7.5、JDK8、elasticsearch-jdbc-2.3.2.0
安装步骤:
- 这里是列表文本第一步:下载(可能很卡、请耐心等待) wgethttp://xbib.org/repository/org/xbib/elasticsearch/importer/elasticsearch-jdbc/2.3.2.0/elasticsearch-jdbc-2.3.2.0-dist.zip
- 这里是列表文本第二步:解压 unzip elasticsearch-jdbc-2.3.2.0-dist.zip
- 这里是列表文本第三步:配置脚本mysql_import_es.sh
#!/bin/sh# elasticsearch-jdbc 安装路径bin=/home/elasticsearch-jdbc-2.3.2.0/binlib=/home/elasticsearch-jdbc-2.3.2.0/libecho '{"type" : "jdbc","jdbc": {# 如果数据库中存在Json文件 这里设置成false,否则会同步出错"detect_json":false,"url":"jdbc:mysql:
//127.0.0.1:3306/itstyle_log??useUnicode=true&characterEncoding=utf-8&useSSL=false&allowMultiQueries=true","user":"root","password":"root",# 如果想自动生成_id,去掉第一个获取字段即可;如果想Id作为主键,把id设置为_id即可"sql":"SELECT id AS _id,id,user_id AS userId ,username,operation,time,method,params,ip,device_type AS deviceType,log_type AS logType,exception_detail AS exceptionDetail,gmt_create AS gmtCreate,plat_from AS platFrom FROM sys_log","elasticsearch" : {"host" : "127.0.0.1",#elasticsearch服务地址"port" : "9300" #远程elasticsearch服务 此端口一定要开放},"index" : "elasticsearch",# 索引名相当于库"type" : "sysLog" # 类型名相当于表}}' | java \-cp "${lib}/*" \-Dlog4j.configurationFile=${bin}/log4j2.xml \org.xbib.tools.Runner \org.xbib.tools.JDBCImporter
- 这里是列表文本第四部:授权并执行
chmod +x mysql_import_es.sh./mysql_import_es.sh
Repository和Template
Spring-data-elasticsearch是Spring提供的操作ElasticSearch的数据层,封装了大量的基础操作,通过它可以很方便的操作ElasticSearch的数据。
ElasticSearchRepository的基本使用
@NoRepositoryBeanpublic interface ElasticsearchRepository<T, ID extends Serializable> extends ElasticsearchCrudRepository<T, ID> {<S extends T> S index(S entity);Iterable<T> search(QueryBuilder query);Page<T> search(QueryBuilder query, Pageable pageable);Page<T> search(SearchQuery searchQuery);Page<T> searchSimilar(T entity, String[] fields, Pageable pageable);void refresh();Class<T> getEntityClass();}
ElasticsearchRepository里面有几个特殊的search方法,这些是ES特有的,和普通的JPA区别的地方,用来构建一些ES查询的。 主要是看QueryBuilder和SearchQuery两个参数,要完成一些特殊查询就主要看构建这两个参数。
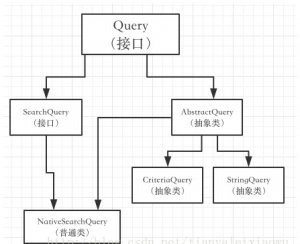
一般情况下,我们不是直接是new NativeSearchQuery,而是使用NativeSearchQueryBuilder。 通过NativeSearchQueryBuilder.withQuery(QueryBuilder1).withFilter(QueryBuilder2).withSort(SortBuilder1).withXXXX().build();这样的方式来完成NativeSearchQuery的构建。
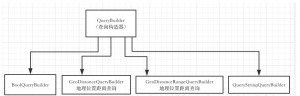
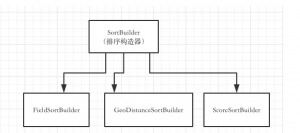
ElasticSearchTemplate的使用
ElasticSearchTemplate更多是对ESRepository的补充,里面提供了一些更底层的方法。
这里我们主要实现快读批量插入的功能,插入20万条数据,本地向外网服务器(1核1G),用时60s+,一分钟左右的时间。虽然索引库容量有增加,但是等了大约10分钟左右的时间才能搜索出来。
//批量同步或者插入数据public void bulkIndex(List<SysLogs> logList) {long start = System.currentTimeMillis();int counter = 0;try {List<IndexQuery> queries = new ArrayList<>();for (SysLogs log : logList) {IndexQuery indexQuery = new IndexQuery();indexQuery.setId(log.getId()+ "");indexQuery.setObject(log);indexQuery.setIndexName("elasticsearch");indexQuery.setType("sysLog");//也可以使用IndexQueryBuilder来构建//IndexQuery index = new IndexQueryBuilder().withId(person.getId() + "").withObject(person).build();queries.add(indexQuery);if (counter % 1000 == 0) {elasticSearchTemplate.bulkIndex(queries);queries.clear();System.out.println("bulkIndex counter : " + counter);}counter++;}if (queries.size() > 0) {elasticSearchTemplate.bulkIndex(queries);}long end = System.currentTimeMillis();System.out.println("bulkIndex completed use time:"+ (end-start));} catch (Exception e) {System.out.println("IndexerService.bulkIndex e;" + e.getMessage());throw e;}}
开源项目源码(参考):https://gitee.com/52itstyle/spring-boot-elasticsearch
- 安卓客户端下载
- 微信扫一扫
-

- 微信公众号
- 微信公众号扫一扫
-