- A+
绪论
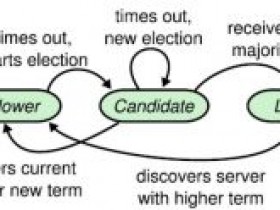
选举是raft共识协议的重要组成部分,重要的功能都将是由选举出的leader完成。不像Paxos,选举对Paxos只是性能优化的一种方式。选举是raft集群启动后的第一件事,没有leader,集群将不允许任何的数据更新操作。选举完成以后,集群会通过心跳的方式维持leader的地位,一旦leader失效,会有新的follower起来竞选leader。
详细流程
选举的发起,一般是从Follower检测到心跳超时开始的,v3支持客户端指定某个节点强行开始选举。选举的过程其实很简单,就是一个candidate广播选举请求,如果收到多数节点同意就把自己状态变成leader。
下图是选举和心跳的详细处理流程。我们将在下文详细描述这个图中的每个步骤。
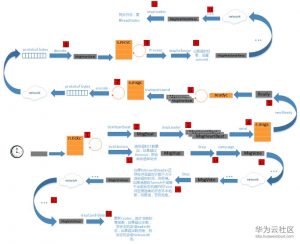
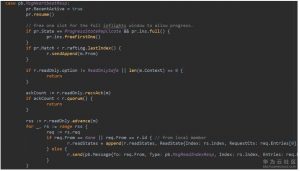
1. tick
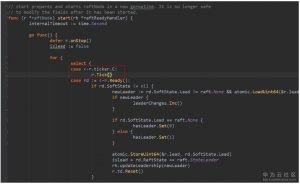
raftNode的创建函数newRaftNode会创建一个Ticker。传入的heartbeat默认为100ms,可以通过–heartbeat-interval配置。
func newRaftNode(cfg raftNodeConfig) *raftNode {
r := &raftNode{
raftNodeConfig: cfg,
// set up contention detectors for raft heartbeat message.
// expect to send a heartbeat within 2 heartbeat intervals.
td: contention.NewTimeoutDetector(2 * cfg.heartbeat),
readStateC: make(chan raft.ReadStateJ
1),
nisgSnapC: make(chan raftpb.Messagej maxInFLightMsgSnap),
applyc: make(chan apply) ^
stopped: make(chan struct{})j
done: make(chan struct{})j
>
if r.heartbeat ss 0 {
r.ticker s &time.Ticker{}
} else {
r.ticker = time.NewTicker(r.heartbeat)
return r
}
}
}
这里要介绍一下代码中出现的几个变量,我把这几个变量都翻译成XXX计数,是因为这些值都是整数,初始化为0,每次tick完了以后会递增1。因此实际这是一个计数。也就是说实际的时间是这个计数值乘以tick的时间。
1. 选举过期计数(electionElapsed):主要用于follower来判断leader是不是正常工作,如果这个值递增到大于随机化选举超时计数(randomizedElectionTimeout),follower就认为leader已挂,它自己会开始竞选leader。
2. 心跳过期计数(heartbeatElapsed):用于leader判断是不是要开始发送心跳了。只要这个值超过或等于心跳超时计数(heartbeatTimeout),就会触发leader广播heartbeat信息。
3. 心跳超时计数(heartbeatTimeout):心跳超时时间和tick时间的比值。当前代码中是写死的1。也就是每次tick都应该发送心跳。实际上tick的周期就是通过–heartbeat-interval来配置的。
4. 随机化选举超时计数(randomizedElectionTimeout):这个值是一个每次任期都不一样的随机值,主要是为了避免分裂选举的问题引入的随机化方案。这个时间随机化以后,每个竞选者发送的竞选消息的时间就会错开,避免了同时多个节点同时竞选。从代码中可以看到,它的值是[electiontimeout, 2*electiontimeout-1] 之间,而electionTimeout就是下图中的ElectionTicks,是ElectionMs相对于TickMs的倍数。ElectionMs是由–election-timeout来配置的,TickMs就是–heartbeat-interval。

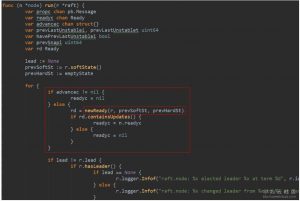
raftNode的start()方法启动的协程中,会监听ticker的channel,调用node的Tick方法,该方法往tickc通道中推入一个空对象。(流程图中1)
node启动时是启动了一个协程,处理node的里的多个通道,包括tickc,调用tick()方法。该方法会动态改变,对于follower和candidate,它就是tickElection,对于leader和,它就是tickHeartbeat。tick就像是一个etcd节点的心脏跳动,在follower这里,每次tick会去检查是不是leader的心跳是不是超时了。对于leader,每次tick都会检查是不是要发送心跳了。
2. leader的任务:发送心跳
当集群已经产生了leader,则leader会在固定间隔内给所有节点发送心跳。其他节点收到心跳以后重置心跳等待时间,只要心跳等待不超时,follower的状态就不会改变。
具体的过程如下:
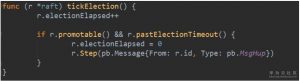
1. 对于leader,tick被设置为tickHeartbeat,tickHeartbeat会产生增长递增心跳过期时间计数(heartbeatElapsed),如果心跳过期时间超过了心跳超时时间计数(heartbeatTimeout),它会产生一个MsgBeat消息。心跳超时时间计数是系统设置死的,就是1。也就是说只要1次tick时间过去,基本上会发送心跳消息。发送心跳首先是调用状态机的step方法。(流程图中2)
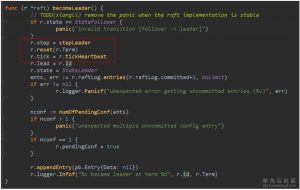
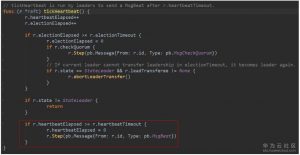
2. step在leader状态下为stepLeader(),当收到MsgBeat时,它会调用bcastHeartbeat()广播MsgHeartbeat消息。构造MsgHeartbeat类型消息时,需要在Commit字段填入当前已经可以commit的消息index,如果该index大于peer中记录的对端节点已经同步的日志index,则采用对端已经同步的日志index。Commit字段的作用将在接收端处理消息时详细介绍。(流程图中3)


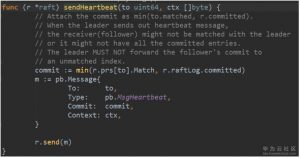
3. send方法将消息append到msgs数组中。(流程图中4)
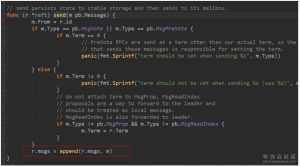
4. node启动的协程会收集msgs中的消息,连同当前未持久化的日志条目、已经确定可以commit的日志条目、变化了的softState、变化了的hardState、readstate一起打包到Ready数据结构中。这些都是会引起状态机变化的,所以都封装在一个叫Ready的结构中,意思是这些东西都已经没问题了,该持久化的持久化,该发送的发送。(流程图中5)
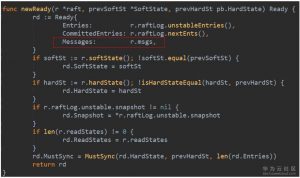
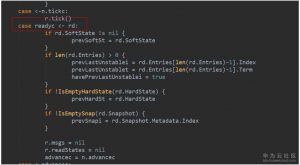
5. 还是raftNode.start()启动的那个协程,处理readyc通道。如果是leader,会在持久化日志之前发送消息,如果不是leader,则会在持久化日志完成以后发送消息。(流程图中6)
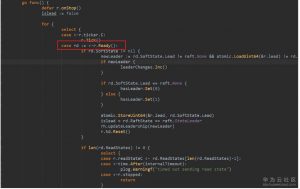
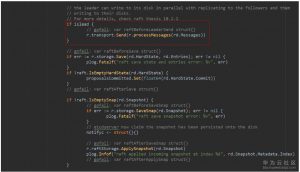
6. transport的Send一般情况下都是调用其内部的peer的send()方法发送消息。peer的send()方法则是将消息推送到streamWriter的msgc通道中。
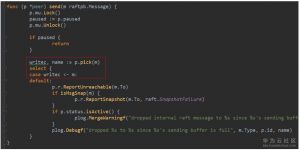
7. streamWriter有一个协程处理msgc通道,调用encode,使用protobuf将Message序列化为bytes数组,写入到连接的io通道中。(流程图中7)
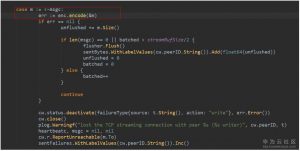

8. 对方的节点有streamReader会接收消息,并反序列化为Message对象。然后将消息推送到peer的recvc或者propc通道中。(流程图中8)
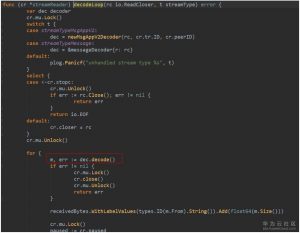

9. peer启动时启动了两个协程,分别处理recvc和propc通道。调用Raft.Process处理消息。EtcdServer是这个接口的实现。(流程图中9)
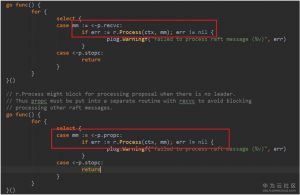
10. EtcdServer判断消息来源的节点是否被删除,没有的话调用Step方法,传入消息,执行状态机的步进。而接收heartbeat的节点状态机正常情况下都是follower状态。因此就是调用stepFollower进行步进。(流程图中10)
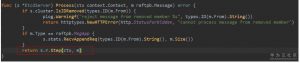
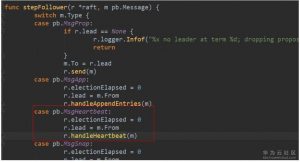

follower对heatbeat消息的处理是:先将选举过期时间计数(electionElapsed)归零。这个时间会在每次tickElection调用时递增。如果到了electionTimeout,就会重新选举。另外,我们还可以看到这里handleHeartbeat中,会将本地日志的commit值设置为消息中带的Commit。这就是第2步说到设置Commit的目的,heartbeat消息还会把leader的commit值同步到follower。同时,leader在设置消息的Commit时,是取它对端已经同步的日志最新index和它自己的commit值中间较小的那个,这样可以保证如果有节点同步比较慢,也不会把commit值设置成了它还没同步到的日志。
最后,follower处理完以后会回复一个MsgHeartbeatResp消息。
11. 回复消息的中间处理流程和心跳消息的处理一致,因此不再赘述。leader收到回复消息以后,最后会调用stepLeader处理回复消息。(流程图中11)
12. stepLeader收到回复消息以后,会判断是不是要继续同步日志,如果是,就发送日志同步信息。另外会处理读请求,这部分的处理将在linearizable读请求的流程中详细解读。
3. 选举
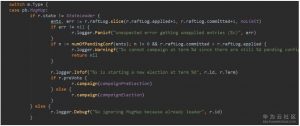
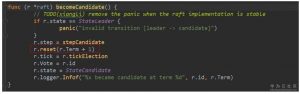
2. Step方法处理MsgHup消息,查看当前本地消息中有没有没有作用到状态机的配置信息日志,如果有的话,是不能竞选的,因为集群的配置信息有可能会出现增删节点的情况,需要保证各节点都起作用以后才能进行选举操作。从图上可以看到,如果有PreVote的配置,会有一个PreElection的分支。这个放在最后我们介绍。我们直接看campaign()方法,它首先将自己变成candidate状态,becomeCandidate会将自己Term+1。然后拿到自己当前最新的日志Term和index值。把这些都包在一个MsgVote消息中,广播给所有的节点。最新的日志Term和index值是非常重要的,它能保证新选出来的leader中一定包含之前已经commit的日志,不会让已经commit的日志被新leader改写。这个在后面的流程中还会讲到。(流程图中14)
3. 选举消息发送的流程和所有消息的流程一样,不在赘述。(流程图中15)
4. 心跳消息到了对端节点以后,进行相应的处理,最终会调到Step方法,进行状态机步进。Step处理MsgVote方法的流程是这样的:
- 首先,如果选举过期时间还没有超时,将拒绝这次选举请求。这是为了防止有些follower自己的原因没收到leader的心跳擅自发起选举。
- 如果r.Vote已经设置了,也就是说在一个任期中已经同意了某个节点的选举请求,就会拒绝选举
- 如果根据消息中的LogTerm和Index,也就是第2步传进来的竞选者的最新日志的index和term,发现竞选者比当前节点的日志要旧,则拒绝选举。
- 其他情况则赞成选举。回复一个赞成的消息。(流程图中16)
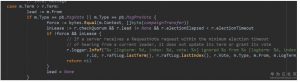


5. 竞选者收到MsgVoteResp消息以后,stepCandidate处理该消息,首先更新r.votes。r.votes是保存了选票信息。如果同意票超过半数,则升级为leader,否则如果已经获得超过半数的反对票,则变成follower。(流程图中18)
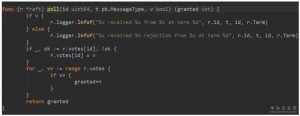
PreVote
PreVote是解决因为某个因为网络分区而失效的节点重新加入集群以后,会导致集群重新选举的问题。
问题出现的过程是这样的,假设当前集群的Term是1,其中一个节点,比如A,它因为网络分区,接收不到leader的心跳,当超过选举超时时间以后,它会将自己变成Candidate,这时候它会把它的Term值变成2,然后开始竞选。当然这时候是不可能竞选成功的。可是当网络修复以后,无论是它的竞选消息,还是其他的回复消息,都会带上它的Term,也就是2。而这时候整个集群里其他机器的Term还是1,这时候的leader发现已经有比自己Term高的节点存在,它就自己乖乖降级为follower,这样就会导致一次重新选举。
这种现象本身布常见,而且出现了也只是出现一次重选举,对整个集群的影响并不大。但是如果希望避免这种情况发生,依然是有办法的,办法就是PreVote。
PreVote的做法是:当集群中的某个follower发现自己已经在选举超时时间内没收到leader的心跳了,这时候它首先不是直接变成candidate,也就不会将Term自增1。而是引入一个新的环境叫PreVote,我们就将它称为预选举吧。它会先广播发送一个PreVote消息,其他节点如果正常运行,就回复一个反对预选举的消息,其他节点如果也失去了leader,才会有回复赞成的消息。节点只有收到超过半数的预选举选票,才会将自己变成candidate,发起选举。这样,如果是这个单个节点的网络有问题,它不会贸然自增Term,因此当它重新加入集群时。也不会对现任leader地位有任何冲击。保证了系统更稳定的方式运行。
如何保证已经commit的数据不会被改写?
etcd集群的leader会一直向follower同步自己的日志,如果follower发现自己的日志和leader不一致,会删除它本地的不一致的日志,保证和leader同步。
leader在运行过程中,会检查同步日志的回复消息,如果发现一条日志已经被超过半数的节点同步,则把这条日志记为committed。随后会进行apply动作,持久化日志,改变kv存储。
我们现在设想这么一个场景:一个集群运行过程中,leader突然挂了,这时候就有新的follower竞选leader。如果新上来的leader日志是比较老的,那么在同步日志的时候,其他节点就会删除比这个节点新的日志。要命的是,如果这些新的日志有的是已经提交了的。那么就违反了已经提交的日志不能被修改的原则了。
怎么避免这种事情发生呢?
这就涉及到刚才选举流程中一个动作,candidate在发起选举的时候会加上当前自己的最新的日志index和term。follower收到选举消息时,会根据这两个字段的信息,判断这个竞选者的日志是不是比自己新,如果是,则赞成选举,否则投反对票。
为什么这样可以保证已经commit的日志不会被改写呢?
因为这个机制可以保证选举出来的leader本地已经有已经commit的日志了。
为什么这样就能保证新leader本地有已经commit的日志呢?
因为我们刚才说到,只有超过半数节点同步的日志,才会被leader commit,而candidate要想获得半数以上的选票,日志就一定要比半数以上的节点新。这样两个半数以上的群体里交集中,一定至少存在一个节点。这个节点的日志肯定被commit了。因此我们只要保证竞选者的日志被大多数节点新,就能保证新的leader不会改写已经commit的日志。
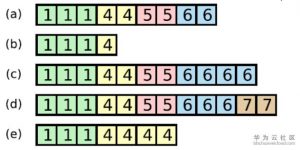
简单来说,这种机制可以保证下图的b和e肯定选不leader。
频繁重选举的问题
如果etcd频繁出现重新选举,会导致系统长时间处于不可用状态,大大降低了系统的可用性。
什么原因会导致系统重新选举呢?
1. 网络时延和网络拥塞:从心跳发送的流程可以看到,心跳消息和其他消息一样都是先放到Ready结构的msgs数组中。然后逐条发送出去,对不同的节点,消息发送不会阻塞。但是对相同的节点,是一个协程来处理它的msgc通道的。也就是说如果有网络拥塞,是有可能出现其他的消息拥塞通道,导致心跳消息不能及时发送的。即使只有心跳消息,拥塞引起信道带宽过小,也会导致这条心跳消息长时间不能到达对端。也会导致心跳超时。另外网络延时会导致消息发送时间过程,也会引起心跳超时。另外,peer之间通信建链的超时时间设置为1s+(选举超时时间)*1/5 。也就是说如果选举超时设置为5s,那么建链时间必须小于2s。在网络拥塞的环境下,这也会影响消息的正常发送。

2. io延时:从apply的流程可以看到,发送msg以后,leader会开始持久化已经commit的日志或者snapshot。这个过程会阻塞这个协程的调用。如果这个过程阻塞时间过长,就会导致后面的msgs堵在那里不能及时发送。根据官网的解释,etcd是故意这么做的,这样可以让那些io有问题的leader自动失去leader地位。让io正常的节点选上leader。但是如果整个集群的节点io都有问题,就会导致整个集群不稳定。
- 安卓客户端下载
- 微信扫一扫
-

- 微信公众号
- 微信公众号扫一扫
-