- A+
摘要: 综合了一些云上ECS Linux系统常见问题涉及知识,方便大家自行排查时候作一些参考。
这里综合了一些云上ECS Linux系统常见问题涉及知识和排查工具,方便大家自行排查时候作一些参考。
一、磁盘/分区操作
分区操作
- fdisk
- parted
文件系统操作
- mount/umount - 挂载/卸载文件系统
- mkfs - 创建文件系统
- fsck - 文件系统检查和修复
- tune2fs - 调整/查看文件系统
- resize2fs - resize文件系统
- debugfs
文件
- /proc/mounts
- /proc/partitions
- /etc/mtab
- /etc/fstab
[root@iXXXXXXX ~]# cat /etc/fstab # # /etc/fstab # Created by anaconda on Thu Feb 23 07:28:22 2017 # # Accessible filesystems, by reference, are maintained under '/dev/disk' # See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info # UUID=3d083579-f5d9-4df5-9347-8d27925805d4 / ext4 defaults 1 1 tmpfs /dev/shm tmpfs defaults 0 0 devpts /dev/pts devpts gid=5,mode=620 0 0 sysfs /sys sysfs defaults 0 0 proc /proc proc defaults 0 0 /dev/vdb1 /mnt ext3 defaults 0 0
常见问题
1、开机进入紧急模式(Emergency Mode)
现象:

解法:
-
/var/logs
-
journalctl -xb
2、文件系统异常
现象:
-
启动异常,提示文件系统有问题
-
进入系统发现磁盘是只读状态
-
一些命令执行或者程序运行异常,报错可能提示文件系统错误
解法:
异常示例:

数据盘:请umount后直接执行
fsck <文件系统分区> -y
系统盘:确保做好快照后工单联系售后处理。
3、磁盘分区/扩容失败
二、系统性能资源
CPU
查询cpu信息
cat /proc/cpuinfo
进程状态
D Uninterruptible sleep (usually IO)R Running or runnable (on run queue)S Interruptible sleep (waiting for an event to complete)T Stopped, either by a job control signal or because it is being traced.Z Defunct ("zombie") process, terminated but not reaped by its parent
查询进程状态和资源消耗
ps auxfUSER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMANDps -eLfUID PID PPID LWP C NLWP STIME TTY TIME CMDtoppidstatvmstat
查询线程CPU资源
ps -eT -o%cpu,pid,tid,ppid,comm | sort -n -r | head -20
查看进程运行在哪个CPU核上
ps -eo pid,psr
关于Load
cat /proc/loadavg
基础命令
top
free -h
cat /proc/meminfo
atop
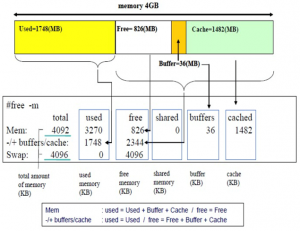
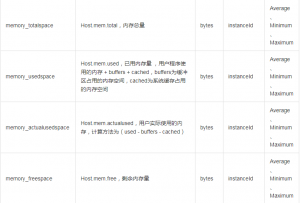
内存占用前20的进程
ps -e -o%mem,pid,tid,ppid,comm | sort -n -r | head -20
slab缓存
cat /proc/slabinfo
slabtop #display kernel slab cache information in real time
echo "3">/proc/sys/vm/drop_caches
Writing to this will cause the kernel to drop clean caches, dentries and inodes from memory, causing that memory to become free.
To free pagecache:
To free dentries and inodes:
To free pagecache, dentries and inodes:
As this is a non-destructive operation, and dirty objects are notfreeable, the user should run "sync" first in order to make sure allcached objects are freed.This tunable was added in 2.6.16.
Out Of Memory (OOM)

echo -17 > /proc/<PID>/oom_adj
[root@iZbp1cvnme86y07zhd1mfiZ /]# cat /usr/include/linux/oom.h #ifndef __INCLUDE_LINUX_OOM_H #define __INCLUDE_LINUX_OOM_H /* /proc//oom_score_adj set to OOM_SCORE_ADJ_MIN disables oom killing for pid. */ #define OOM_SCORE_ADJ_MIN (-1000) #define OOM_SCORE_ADJ_MAX 1000 /* /proc//oom_adj set to -17 protects from the oom killer for legacy purposes. */ #define OOM_DISABLE (-17) / inclusive / #define OOM_ADJUST_MIN (-16) #define OOM_ADJUST_MAX 15 #endif / __INCLUDE_LINUX_OOM_H /
echo f> /proc/sysrq-trigger
工具
iostat
dstat
sar - [-b #Display io statistics]
df - 检查文件系统使用磁盘空间
du - 检查文件使用磁盘空间
fio - 磁盘性能压测
一般对磁盘性能有疑问,建议用fio压测磁盘,压测时候避免有其他业务运行影响结果。
命令参考:
https://help.aliyun.com/document_detail/25382.html
常用工具:
网络监测:
ping - ICMP包测试,[-s #Size in byte] [-i #Interval in second]
telnet - 测试端口连通性
nmap - 网络探测&扫描工具,基础使用[nmap <ip> <ip> <ip>] [nmap <ip/mask>] [-Pn #Ports scan without ping host check]
traceroute - 路由跟踪,[-I #using ICMP] [-T #using TCP SYN],默认用UDP
mtr - 网络诊断,[-c #Probes per second] [-s #ICMP packet size] [-T #Using TCP SYN] [-P #Specify port number] -u #Using UDP]
网络分析:
ss - 查询socket统计信息,[-s #Summary statistics] [-ant #]
sar - 系统资源使用统计,[-n #Specify network] [DEV #Network usage for all interfaces] [EDEV #Network failure/errors count]
sar -n DEV
输出项说明:
IFACE 网络设备名
rxpck/s 每秒接收的包总数
txpck/s 每秒传输的包总数
rxbyt/s 每秒接收的字节(byte)总数
txbyt/s 每秒传输的字节(byte)总数
rxcmp/s 每秒接收压缩包的总数
txcmp/s 每秒传输压缩包的总数
rxmcst/s 每秒接收的多播(multicast)包的总数
netstat - 查询连接情况
netstat -s #连接信息统计汇总 netstat -i #接口网络统计 netstat -nltp #进程TCP监听信息 netstat -nlup #进程UDP监听信息 netstat -ano #列出监听和连接信息
tcpdump - 抓包
tcpdump -i <interface # any|eth0|eth1...> host <ip> port <port number> tcpdump -i any port 53 #抓DNS请求 tcpdump -i any host 1.1.1.1 port 80 #抓包含ip 1.1.1.1和port 80的包 nohup tcpdump -i any -C 30 -W 50 -w /tmp/net.pcap & #后台循环抓包50M*30
测试下载
网络解析
防火墙
网络配置
配置文件
SSH
默认22端口
/etc/ssh/
/etc/ssh/ssh_config #ssh客户端配置文件
/etc/ssh/sshd_config #ssh服务端配置文件
详细解读和问题汇总
https://help.aliyun.com/knowledge_detail/52874.html
verbose & debug
客户端启用verbose日志: ssh -vvv
服务端开启debug模式:/usr/sbin/sshd -p <testport> -d
定时任务
系统MAC时间
cron&anacron

*/bin/run-parts用于执行整个目录的可执行程序。
*基于日、周、月的cron任务是通过anacron来跑的,crond执行/etc/cron.hourly/0anacron会去检查当天/周/月对应anacron是不是跑过,没跑过才会调用/usr/sbin/anacron。
*系统日志默认是每周滚动,但是对应文件是在/etc/cron.daily下
简单概括功能的话,cron基于时间进行定时任务调度,而anacron不依赖于系统持续运行,方便实现异步的周期性任务。
crontab -l #列出当前用户定时任务
crontab -e #配置当前用户定时任务
/var/log/cron*
logrotate
Linux系统提供了logrotate这个工具来方便地实现日志滚动,默认通过cron每日执行
cron和logrotate详细介绍:https://www.atatech.org/articles/90434
系统时间
date
hwclock/clock
ntpd
基于ntp server校准系统时间和时钟频率。一般服务器先ntpdate同步时间后,再启用ntpd进行逐渐校正。
/etc/timezone #当前时区描述
ntpdate
基于ntp server同步系统时间
timedatectl
设置系统日期和时间
- 安卓客户端下载
- 微信扫一扫
-

- 微信公众号
- 微信公众号扫一扫
-