- A+
有一类比较特殊的CPU使用率问题,这类问题的特点是,系统平均CPU使用率很低,但是个别CPU的使用率非常高。今天借助这个真实案例,来跟大家探讨一下这类问题的解题思路。
四平八稳的kworker进程
闲里偷忙
在多核环境里,我们能见到的,CPU使用率的问题,大多是每个CPU的使用率都比较高。进程调度算法的一个最主要目标,就是保证不会有有的人撑死,有的人饿死的情况发生。能影响这种“公平性”的因素有两个,一个是优先级(priority),另外一个是相关性(affinity)。优先级处理的是进程之间,哪个比较重要的问题;相关性处理的是进程需要某一个CPU专门负责的问题。
相关性会引起“闲里偷忙”这种问题是显而易见的。如果一个进程被绑定到某一个CPU,那么如果这个进程持续的做计算,势必会让这一个CPU占用率变高。当前这个问题属于这一类。至于优先级和这类问题的关联,不是那么明显。优先级在一些特殊的状况下,会制造类似的麻烦,有机会我会借助例子来分析。
工作队列
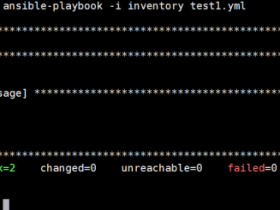
相信观察仔细的同学,会发现第一张图里,kworker进程名字后边跟了24:2这样的标识。这个和大多数其他进程是不一样的。我们先从这两个数字背后的机制,工作队列说起。
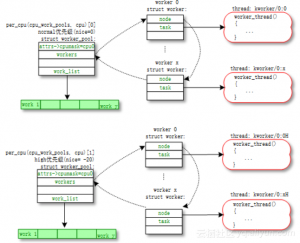
关于工作队列(work queue),这边有五个核心的概念,分别是工作(work,也就是需要做的事情,分装一个函数),工作池(work pool,工作需要一个一个处理,这是一个工作的集合),工人(worker,实现为内核进程),工人小组(worker pool,工人小团队)以及第五个概念,中介。中介是把工作队列和工人小组联系起来的纽带。工作队列这个机制,是为了保证,每一个work,从被放在工作池里,然后经过中介的手,分配给某一个工人小组的某一个工人去处理,这一切都能高效有序的进行。
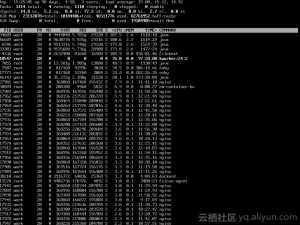
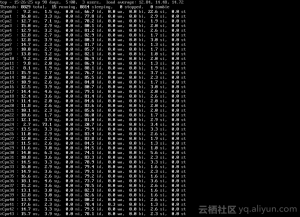
对每个CPU,系统会创建两个的工作小组,普通优先级组,和高优先级组。系统会根据工作多少,动态管理每个工人小组里,工人的数量。下边是从网上拿的一张图,这张图对应一个CPU的(普通优先级在上、高优先级在下)两个工作小组。我们可以看到,每个worker被实现为一个kworker进程。而kworker后边的两个数字,大家应该可以猜到,第一个代表的是CPU的编号,第二个代表着一个工人在工人小组里的编号。当前这个问题中,kworker是第24个CPU的第2个worker。这也是为什么,在第二张图里,第24个CPU的系统使用率高的。
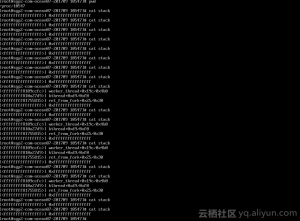
调用栈
ftrace

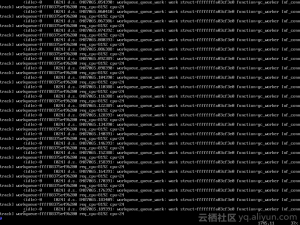
这个日志,能说明三个问题:第一,高CPU使用率并不是某一个有问题的工作导致的,而是很多工作被不断地添加到工作队列里,并分派到24号CPU上导致的;第二,这些工作对应一个函数,就是nf_conntrack这个模块的gc_worker函数;第三,work struct指针从头到尾都没有变化,说明同样一个work被重复添加。
备注:关于ftrace的更多细节,这里不再详述,如果感兴趣,或者用到的时候,请自行Google。
perf
问题进展到这一步,我还是想搞清楚使用CPU资源高的调用栈是什么样子,因为这才是真正的实锤。其间我想到向sysrq-trigger文件写入l字符来产生所有CPU上运行的call stack,但是最终还是怕出事没有做。sysrq确实是一个看起来比较吓人的机制。
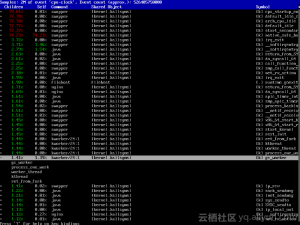
下一个可用的工具是perf,很巧的是,我发现客户系统安装了这个工具。而比这更巧的事情是,我发现客户在root目录下,居然有一份收集好的perf日志。顺手用perf report分析这份日志,得到下边输出。很显然这里有我想要的调用栈。而这个调用栈完全匹配之前用其他工具得到的结果。
源码分析&建议
知道导致问题的调用栈,下边能做的,只有代码分析。
gc_worker是nf_conntrack模块里定义的,用来执行conntrack表项超时回收任务的一个函数,而这个函数会在自己的结尾处,以一定的延迟策略,重新把自己queue到工作队列中去。这也是为什么我们在ftrace日志里看到所有的work struct指针都不变的原因。
确定了问题是由大量gc_worker工作导致的,那么,从逻辑上来讲,有三个方向可以去调优这个问题。第一个是,让gc_worker的工作分摊到所有的CPU上去。但这个方案必须有内核相关配置项支持。可惜的是,工作队列的代码逻辑为了保证效率,采取了就近原则。就是说,一个工作,运行在一个CPU上,去queue另外一个工作,那么被queue的工作也会被放在同样的CPU上执行。第二个是,根据网络环境,优化gc_worker的相关参数。第三个是,把所有业务进程提升到实时优先级,这样,当业务进程被分派到kworker使用的这个CPU的时候,会抢占kworker,从而保证业务不受影响。
在不能修改内核代码的情况下,我强烈建议客户用第三个方案。
客户的选择
- 安卓客户端下载
- 微信扫一扫
-

- 微信公众号
- 微信公众号扫一扫
-