- A+
机制和架构
简介
- 实时的分布式搜索分析引擎
- 内部使用 Lucene 做索引与搜索
目录
- 索引结构和分片
- 集群原理
- 分布式存储
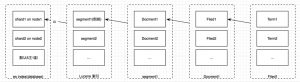
索引结构和分片
一个文档由 _index 、 _type 和 _id 唯一标识一个文档。
_index
指向一个或者多个物理 分片 的 逻辑命名空间
_type
类型用于区分同一个集合中的不同细分,不同的细分中数据的整体模式是相同或相似的,不适合 完全不同类型的数据 ,多个类型可以在相同的索引中存在,只要它们的字段不冲突(对于整个索引,映射在本质上被 扁平化 成一个单一的、全局的模式)。
分片
分片是一个底层的 工作单元,一个分片是一个 Lucene 的实例,它本身就是一个完整的搜索引擎,文档不会跨分片存储。
索引与分片的关系图:
存储目录截图:

一个分片可以是 主 分片或者 副本 分片,索引建立的时候就已经确定了主分片数,副本分片数可以随时修改。
初始化时确定主分片数:
依据硬件情况等定好单个分片容量,依据业务场景预估数据量和增长量,除以单个分片容量。
分片数不够时,可以考虑重建索引,或者使用一个新的索引名称。搜索 1 个有着 50 个分片的索引与搜索 50 个每个都有 1 个分片的索引完全等价。
索引别名
索引 别名 就像一个快捷方式或软连接,可以指向一个或多个索引。可以用于实现索引分组,或者索引间的无缝切换
动态更新索引
倒排索引(Lucene中的段)被写入磁盘后是 不可改变 的:它永远不会修改
es增加新的补充索引来反映新近的修改,而不是直接重写整个倒排索引。每一个倒排索引都会被轮流查询到—从最早的开始–查询完后再对结果进行合并
近实时搜索
按段(per-segment)搜索的发展
新段会被先写入到文件系统缓存,稍后再被刷新到磁盘,只要文件已经在缓存中, 就可以像其它文件一样被打开和读取了。
持久化变更
每一次对 Elasticsearch 进行操作时均记录事务日志,当 Elasticsearch 启动的时候,并且会重放 translog 中所有在最后一次提交后发生的变更操作。
段合并
为节省资源,提高检索效率,Elasticsearch通过在后台进行段合并,小的段被合并到大的段,然后这些大的段再被合并到更大的段。
通过optimize API可以将一个分片强制合并到指定的段数目。 (通常减少到一个)。例如在日志这种用例下,每天、每周、每月的日志被存储在一个索引中。 老的索引实质上是只读的;它们也并不太可能会发生变化
集群原理
客户端请求可以发送到集群的任何节点,每个节点都知道任意文档所处的位置,然后转发这些请求,收集数据,返回给客户端,处理客户端请求的节点成为协调节点。
读取单个文档
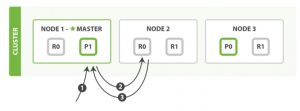
路由信息:

节点类型
主节点
主要负责集群相关操作,管理集群变更。
主节点可以做为协调节点,但尽可能做尽量少的工作,因此生成环境应尽量分离主节点和数据节点,创建独立主节点的配置:
node.master: true
node.data: false
为了防止数据丢失,每个主节点应该知道有资格成为主节点数量,默认为1,为避免网络分区时出现多主的情况,配置discovery.zen.minimum_master_nodes原则:
(master_eligible_nodes / 2)+ 1
数据节点
保存数据、执行数据相关操作,对CPU、内存、IO要求较高
客户端节点
java client
部落节点
特殊的客户端,可以连接多个集群
集群健康状态
green
所有的主分片和副本分片都正常运行。
yellow
所有的主分片都正常运行,但不是所有的副本分片都正常运行。这意味着存在单点故障风险
red
有主分片没能正常运行。
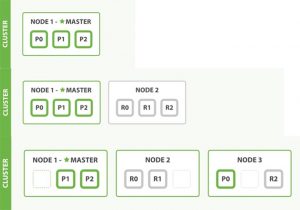
集群扩容
按集群节点来均衡分配这些分片,从而对索引和搜索过程进行负载均衡
复制每个分片以支持数据冗余,从而防止硬件故障导致的数据丢失
当集群只有一个节点,到变成2个节点,3个节点时的 shard 迁移示例图
出现异常
如果主节点异常,重新选举主节点,主分片异常会将副分片提升为主分片
集群状态
集群状态元数据是全局信息,并且在每个节点上保持最新,集群状态由主节点负责维护,主节点从数据节点接受到更新,将这些更新广播到集群的其他节点。
当更新密集时,状态信息可能会非常大,每秒1w条数据时,状态信息可能有几十M。
2.0版本之后,更新的集群状态信息只发diff,并且是被压缩的
分布式存储
文档存储到哪个分片?
shard = hash(routing) % number_of_primary_shards
routing默认是文档ID,可自定义。
由于上面的路由规则,主分片数量不可变
单个写操作(Creating, indexing, or deleting)
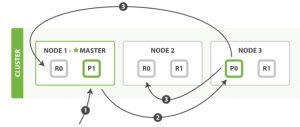
数据写到主分片。默认情况下,主分片 需要 规定数量在写入操作时可用。这是为了防止将数据写入到网络分区的‘`背面’’。规定的数量定义公式如下:
quroum = int( (primary + number_of_replicas) / 2 ) + 1
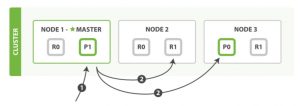
读取单个文档

更新文档
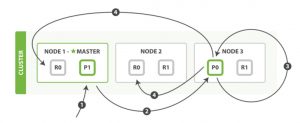
mget读取多个文档
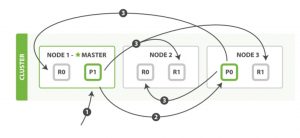
bulk修改多个文档:
- 安卓客户端下载
- 微信扫一扫
-

- 微信公众号
- 微信公众号扫一扫
-